library(ggplot2)
library(dplyr)
library(ipeaplot)- 1
- Pacote para visualização de dados
- 2
- Pacote para transformação de dados
- 3
- Pacote para o padrão Ipea
Gráfico de colunas com proporção de pessoas por categoria de ocupação em cada estado
Nesse exemplo, o objetivo é criar um gráfico de colunas para visualizar a proporção de pessoas por categoria de ocupação para cada estado, em um trimestre específico (nesse caso, utilizaremos os dados do trimestre mais recente)
Para isso, precisamos calcular a proporção de pessoas por categoria de ocupação, em cada estado. Depois, representaremos esses valores em um gráfico de colunas.
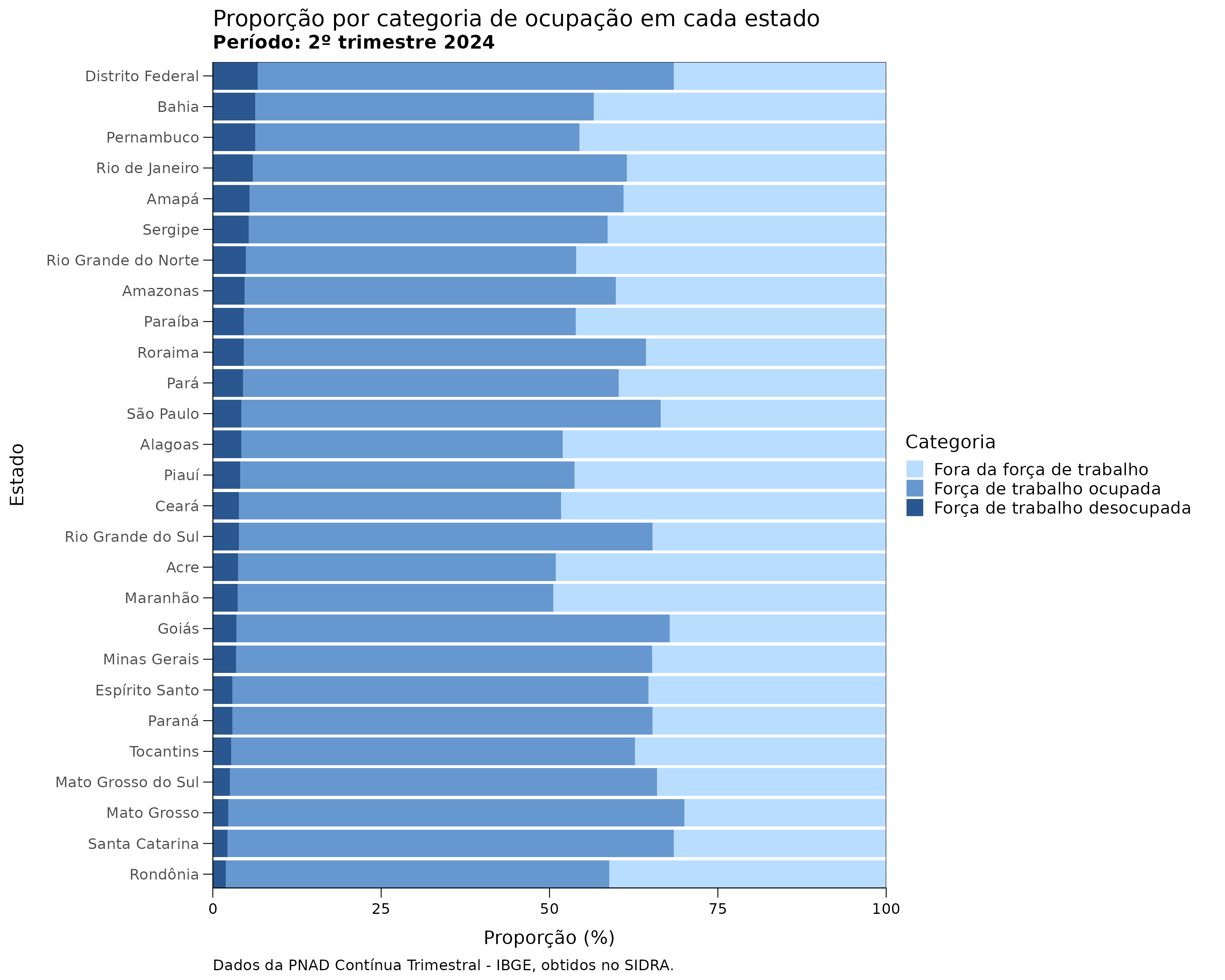
Esse é o gráfico que queremos criar:
library(ggplot2)
library(dplyr)
library(ipeaplot)Caso não tenha o arquivo da tabela que utilizaremos, você pode baixar aqui, e copiar o arquivo para a pasta dados_output do seu projeto.
Outra opção é executar o código abaixo:
download.file(
url = "https://github.com/ipeadata-lab/curso_r_intro_202409/raw/refs/heads/main/dados_output/sidra_4092_arrumado.rds",
destfile = "dados_output/sidra_4092_arrumado.rds",
mode = "wb"
)dados <- readr::read_rds("dados_output/sidra_4092_arrumado.rds")
dados_tri_recente <- dados |>
filter(trimestre_inicio == max(trimestre_inicio))É importante entender as categorias de ocupação que temos disponíveis na base de dados, se não podemos correr o risco de contar valores mais de uma vez:
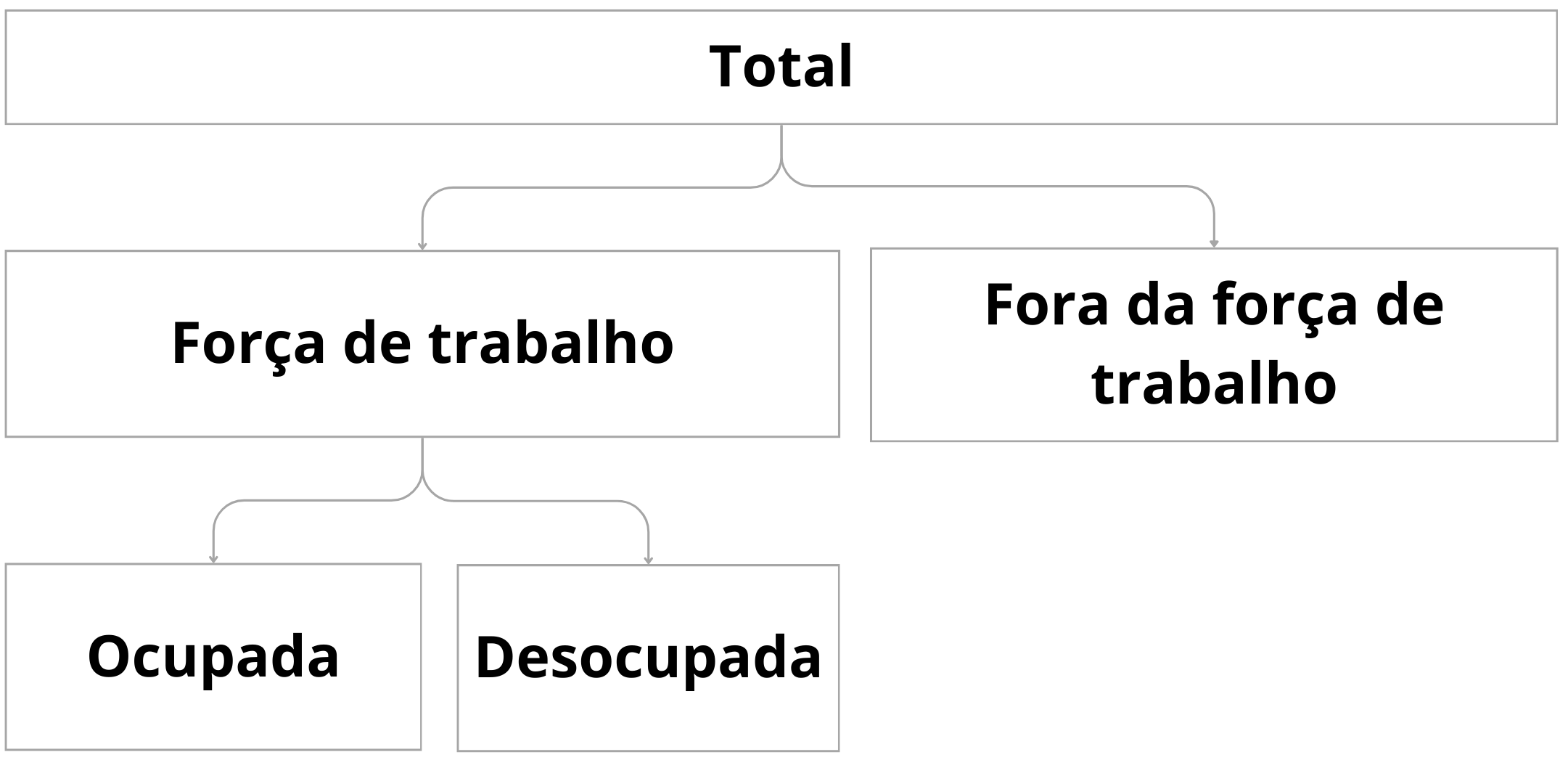
Portanto, para obter o total, precisaremos apenas das seguinte categorias de ocupação:
mil_pessoas_forca_de_trabalho_ocupada: Pessoas dentro da força de trabalho, que estão ocupadas.
mil_pessoas_forca_de_trabalho_desocupada: Pessoas dentro da força de trabalho, que estão desocupadas.
mil_pessoas_fora_da_forca_de_trabalho: Pessoas fora da força de trabalho.
Primeiro, vamos selecionar as colunas que utilizaremos para esse gráfico, para facilitar a preparação dos dados:
dados_selecionados <- dados_tri_recente |>
select(
regiao,
uf,
trimestre,
mil_pessoas_forca_de_trabalho_ocupada,
mil_pessoas_forca_de_trabalho_desocupada,
mil_pessoas_fora_da_forca_de_trabalho,
)
head(dados_selecionados)# A tibble: 6 × 6
regiao uf trimestre mil_pessoas_forca_de…¹ mil_pessoas_forca_de…²
<chr> <chr> <chr> <dbl> <dbl>
1 Nordeste Pernambu… 2º trime… 3774 492
2 Nordeste Bahia 2º trime… 6159 769
3 Centro Oeste Distrito… 2º trime… 1613 174
4 Sudeste Rio de J… 2º trime… 8226 878
5 Nordeste Sergipe 2º trime… 1016 102
6 Nordeste Rio Gran… 2º trime… 1441 144
# ℹ abbreviated names: ¹mil_pessoas_forca_de_trabalho_ocupada,
# ²mil_pessoas_forca_de_trabalho_desocupada
# ℹ 1 more variable: mil_pessoas_fora_da_forca_de_trabalho <dbl>Para calcular a proporção de pessoas por categoria de ocupação em cada estado, precisamos usar os valores que estão nas colunas mil_pessoas_forca_de_trabalho_ocupada, mil_pessoas_forca_de_trabalho_desocupada e mil_pessoas_fora_da_forca_de_trabalho. Porém, para fazer isso, precisamos transformar a tabela em formato longo.
Vamos transformar a tabela em formato longo, utilizando a função pivot_longer():
dados_longos <- dados_selecionados |>
tidyr::pivot_longer(
cols = tidyselect::starts_with("mil_pessoas"),
names_to = "categoria",
values_to = "mil_pessoas",
names_prefix = "mil_pessoas_"
)
head(dados_longos)# A tibble: 6 × 5
regiao uf trimestre categoria mil_pessoas
<chr> <chr> <chr> <chr> <dbl>
1 Nordeste Pernambuco 2º trimestre 2024 forca_de_trabalho_ocupada 3774
2 Nordeste Pernambuco 2º trimestre 2024 forca_de_trabalho_desocupada 492
3 Nordeste Pernambuco 2º trimestre 2024 fora_da_forca_de_trabalho 3574
4 Nordeste Bahia 2º trimestre 2024 forca_de_trabalho_ocupada 6159
5 Nordeste Bahia 2º trimestre 2024 forca_de_trabalho_desocupada 769
6 Nordeste Bahia 2º trimestre 2024 fora_da_forca_de_trabalho 5314Agora, podemos calcular a proporção de pessoas por categoria de ocupação em cada estado:
dados_preparados <- dados_longos |>
group_by(regiao, uf, trimestre) |>
mutate(perc = mil_pessoas / sum(mil_pessoas) * 100) |>
ungroup()
head(dados_preparados)# A tibble: 6 × 6
regiao uf trimestre categoria mil_pessoas perc
<chr> <chr> <chr> <chr> <dbl> <dbl>
1 Nordeste Pernambuco 2º trimestre 2024 forca_de_trabalho_ocu… 3774 48.1
2 Nordeste Pernambuco 2º trimestre 2024 forca_de_trabalho_des… 492 6.28
3 Nordeste Pernambuco 2º trimestre 2024 fora_da_forca_de_trab… 3574 45.6
4 Nordeste Bahia 2º trimestre 2024 forca_de_trabalho_ocu… 6159 50.3
5 Nordeste Bahia 2º trimestre 2024 forca_de_trabalho_des… 769 6.28
6 Nordeste Bahia 2º trimestre 2024 fora_da_forca_de_trab… 5314 43.4 Com os dados preparados, podemos criar o gráfico de colunas. Vamos primeiro criar um gráfico simples:
dados_preparados |>
ggplot(aes(fill = categoria)) +
aes(y = uf, x = perc) +
geom_col()fill (preenchimento) usando a categoria de ocupação.
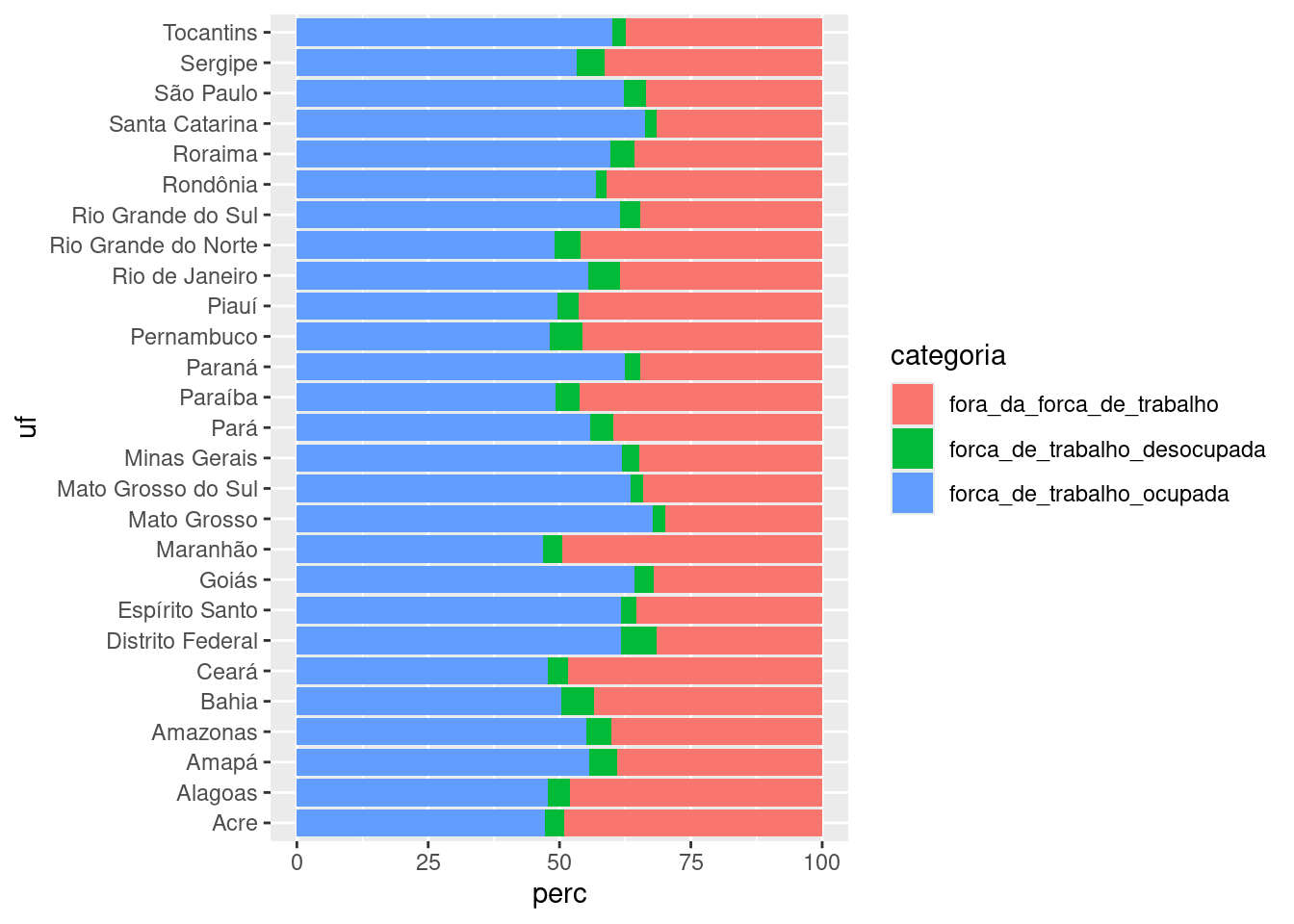
É interessante melhorar as legendas dos eixos, pois estão no formato adequado para nomes de colunas (mas não a melhor forma de apresentar em um gráfico). Isso requer trabalhar novamente na preparação dos dados!
Vamos criar uma nova coluna com os nomes das categorias de ocupação por extenso:
dados_grafico_1 <- dados_preparados |>
mutate(
categoria_label = case_match(
categoria,
"forca_de_trabalho_ocupada" ~ "Força de trabalho ocupada",
"forca_de_trabalho_desocupada" ~ "Força de trabalho desocupada",
"fora_da_forca_de_trabalho" ~ "Fora da força de trabalho"
)
) case_math() (similar ao case_when()), criamos uma nova coluna com os nomes das categorias de ocupação por extenso.
dados_grafico_1 |>
ggplot(aes(fill = categoria_label)) +
aes(y = uf, x = perc) +
geom_col()fill = categoria_label).
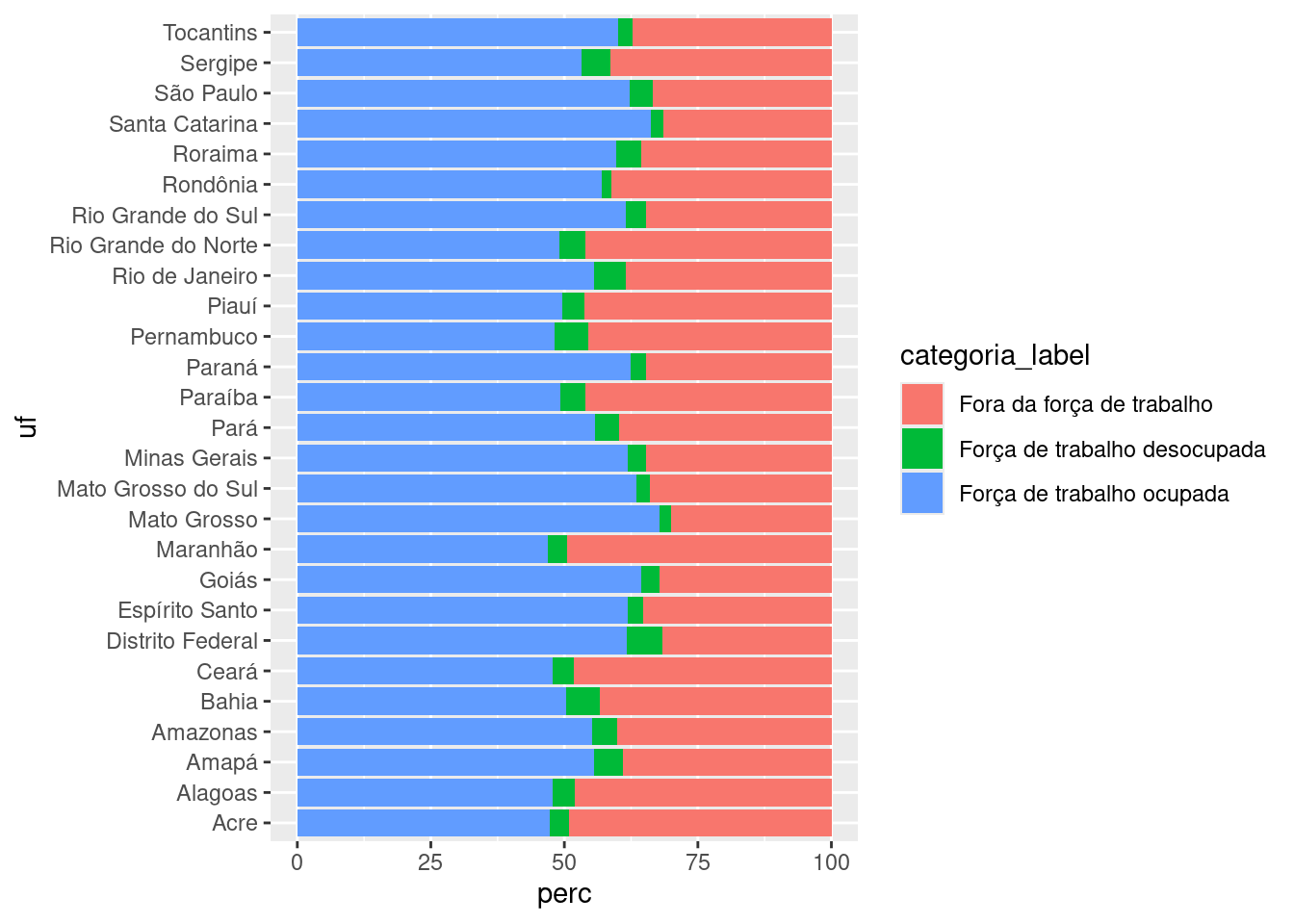
Está um pouco melhor! Outra coisa interessante é reordenar os estados de acordo com a variável perc (proporção de pessoas em cada categoria). Isso fará com que o gráfico fique com aspecto “ordenado”.
dados_grafico_2 <- dados_grafico_1 |>
mutate(
categoria_fct = factor(
categoria_label,
levels = c(
"Fora da força de trabalho",
"Força de trabalho ocupada",
"Força de trabalho desocupada"
)),
uf_fct = forcats::fct_reorder(uf, perc, min)
) uf) de acordo com a proporção de pessoas em cada categoria (perc), usando a função min() para ordenar usando os valores mínimos. Isso faz com que o gráfico fique com aspecto “ordenado”.
dados_grafico_2 |>
ggplot(aes(fill = categoria_fct)) +
aes(y = uf_fct, x = perc) +
geom_col()uf_fct no eixo y.
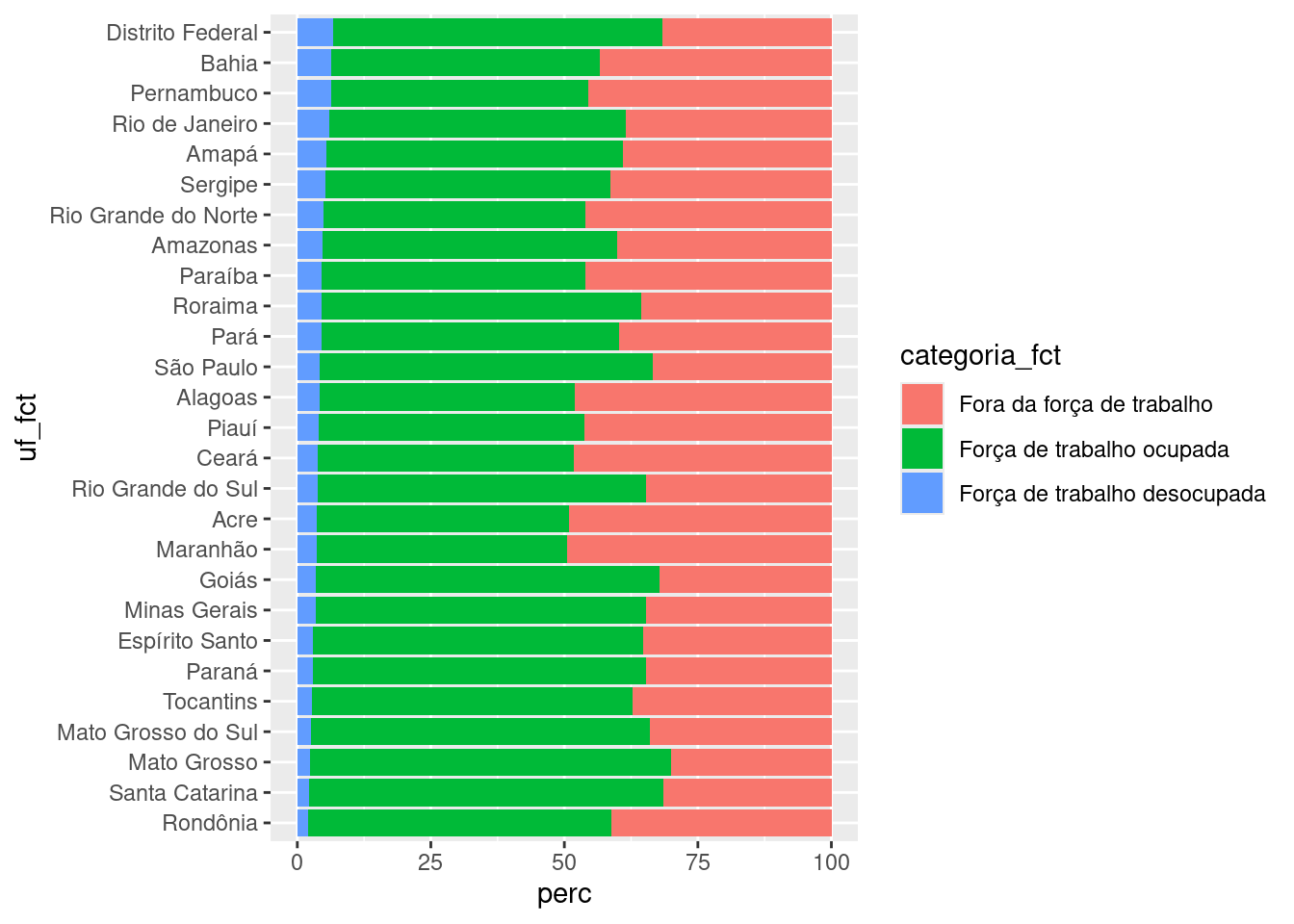
Vamos adicionar títulos, legendas e personalizar as cores do gráfico:
trimestre_referencia <- unique(dados_grafico_2$trimestre)
grafico_proporcao <- dados_grafico_2 |>
ggplot(aes(fill = categoria_fct)) +
aes(x = uf_fct, y = perc) +
geom_col() +
scale_fill_manual(values = c( "#5b5e62", "gray", "#cc1e00")) +
labs(
y = "Proporção (%)",
x = "Estado",
title = "Proporção por categoria de ocupação em cada estado",
subtitle = paste0("Período: ", trimestre_referencia),
fill = "Categoria",
caption = "Dados da PNAD Contínua Trimestral - IBGE, obtidos no SIDRA."
) +
theme_minimal() +
coord_flip()
grafico_proporcaoaes() com fill dentro da função ggplot().
x como os estados e o eixo y como a proporção.
coord_flip() para inverter os eixos x e y.
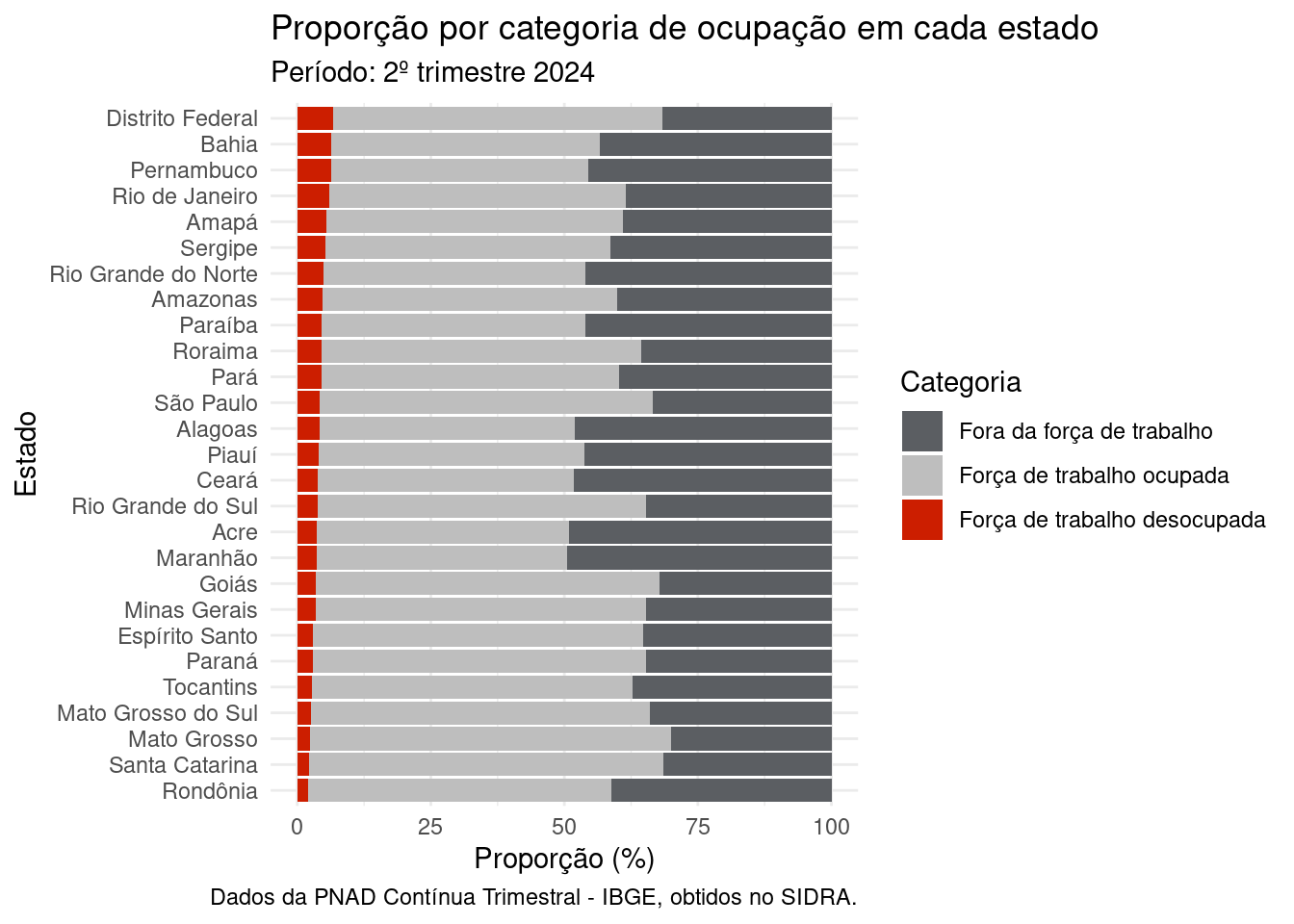
Podemos salvar o gráfico em um arquivo, para utilizá-lo posteriormente:
ggsave(
filename = "graficos/grafico_proporcao_categoria_ocupacao.png",
plot = grafico_proporcao,
width = 10,
height = 8,
dpi = 300
){ipeaplot}: criando graficos no padrão editorial do IpeaO {ipeaplot} é um pacote em R desenvolvido pela equipe da Coordenação de Ciência de Dados (COCD). O objetivo é facilitar a padronização de gráficos e figuras seguindo as linhas editoriais do Ipea.
Ele foi desenhado para ser usado em conjunto com o pacote {ggplot2}. Atualmente, o {ipeaplot} inclui três conjuntos de funções principais:
theme_ipea(): para formatação de elementos estilísticos da figura (eixos, fontes, linhas, grid, etc.);scale_color_ipea() e scale_fill_ipea(): selecionam paleta de cores dentro de um conjunto de opções utilizadas pelo Ipea;save_pdf() e save_eps(): salvam a figura com a extensão .pdf ou .eps, formatos possíveis de serem “modificados” durante o processo de edição das publicações pelo Editorial do Ipea.Tivemos como inspiração outras instituições que criaram ferramentas parecidas como a UNHCR {unhcrthemes} e a BBC {bbplot}.
Vamos primeiro instalar e chamar o pacote:
install.packages("ipeaplot")
library("ipeaplot"){ipeaplot}.
Agora aproveitaremos o exemplo anterior para demonstrar o funcionamnto do {ipeaplot}. Vamos começar a modificar a figura, usando o {ipeaplot} para ajustar ao “padrão do Ipea”. Primeiro usamos a função theme_ipea() no lugar de theme_minimal().
grafico_ipeaplot <- grafico_proporcao +
theme_ipea() +
coord_flip(expand = FALSE)expand = FALSE limita o gráfico à área dos dados (sem espaços em branco antes do valor 0 e depois do valor 100).
Coordinate system already present. Adding new coordinate system, which will
replace the existing one.grafico_ipeaplot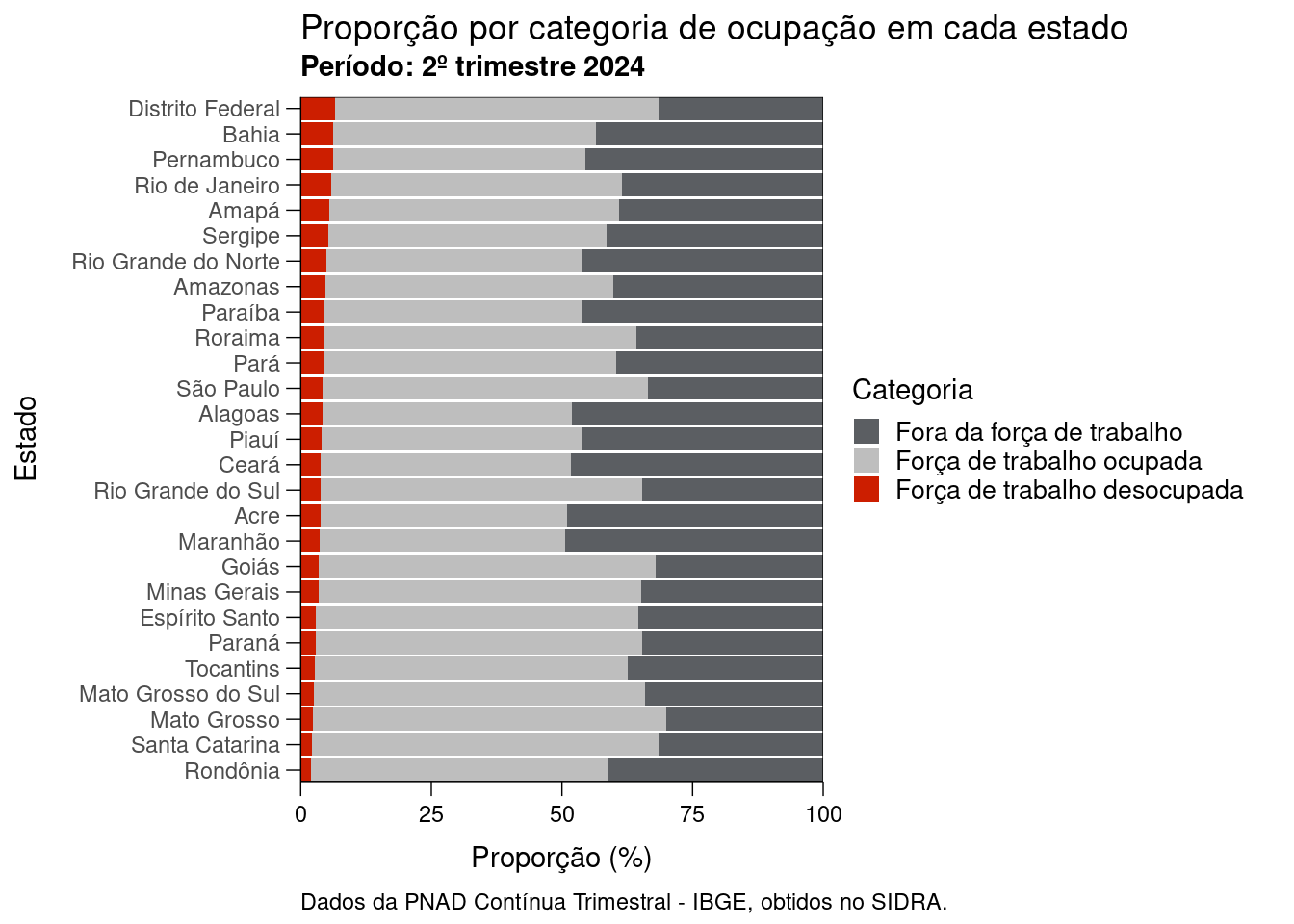
Apesar de sutis, temos alterações nas bordas, nas fontes e nas legendas da figura. Em seguida, vamos mudar a escala de cores para adotar o padrão “Texto para Discussão do Ipea” (paleta de cores azul):
grafico_ipeaplot <- grafico_ipeaplot +
scale_fill_ipea(palette = 'Blue')
grafico_ipeaplot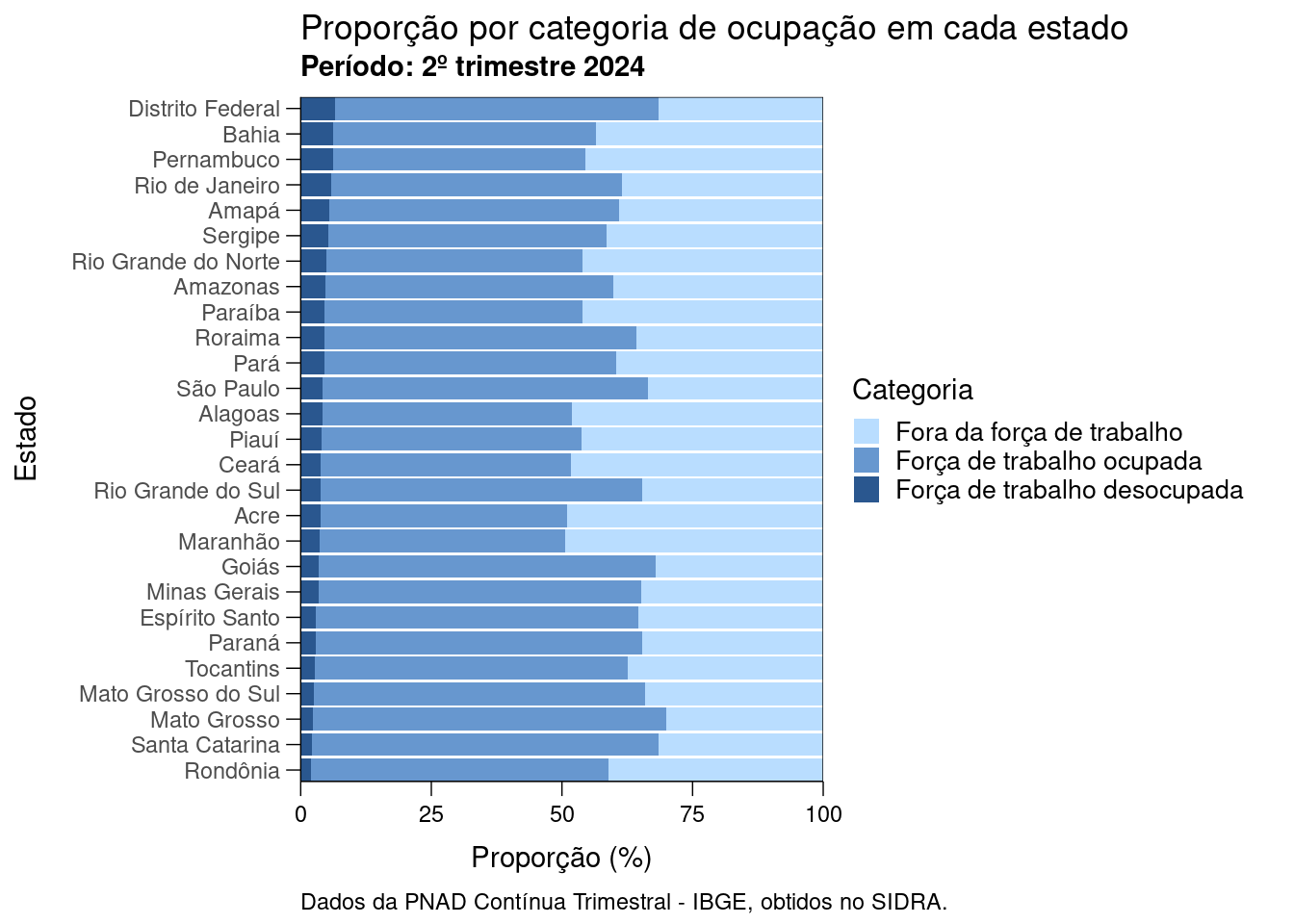
Aí está, temos uma figura pronta para publicarmos nosso primeiro “Texto para Discussão” usando o R. Na verdade, nem tão pronta assim, pois o Ipea usa em títulos e legendas a família de fontes Frutiger. Como não é uma família com licença livre não podemos distribuir no {ipeaplot}. Porém, com o passo a seguir, o Editorial poderá, ao receber seu material para publicação, fazer os ajustes necessários na fonte dos títulos e legendas.
save_eps(grafico_ipeaplot,
file.name = "graficos/grafico_ipeaplot.eps",
width = 10,
height = 8,
dpi = 300
)
save_pdf(grafico_ipeaplot,
file.name = "graficos/grafico_ipeaplot.pdf",
width = 10,
height = 8,
dpi = 300
).eps
.pdf
Por trás das cortinas, as duas funções acima são semelhantes à ggsave(), usada anteriormente nesta aula. Porém, os atributos passados garantem que os gráficos serão salvos em formatos “editáveis” (.eps ou .pdf).