library(dplyr)
dados_brutos <- readr::read_rds("dados/sidrar_4092_bruto.rds") Transformando dados
Introdução
Primeiramente, precisamos carregar o pacote tidyverse e a base de dados que vamos utilizar. A base de dados é a tabela 4092 do SIDRA, que apresenta dados sobre “pessoas de 14 anos ou mais de idade por condição em relação à força de trabalho e condição de ocupação”1, e foi baixada previamente (em Importando dados).
Neste capítulo, vamos explorar as funções de transformação de dados do pacote dplyr, a partir da pergunta norteadora abaixo:
Considerando que a tabela 4092 apresenta dados sobre “pessoas de 14 anos ou mais de idade por condição em relação à força de trabalho e condição de ocupação”, qual é a taxa de desocupação de cada estado e região do Brasil ao longo do tempo?
Linhas, colunas e objetivo de análise
Uma pergunta que é sempre importante ter em mente ao analisar dados é: O que cada linha representa? Na estatística, esse é o conceito da unidade observacional.
O objeto dados_brutos apresenta uma linha para cada combinação das seguintes variáveis:
Trimestre (Código)/TrimestreUnidade da Federação/Unidade da Federação (Código)Variável/Variável (Código)Condição em relação à força de trabalho e condição de ocupaçãoeCondição em relação à força de trabalho e condição de ocupação (Código)
Podemos consultar os valores distintos possíveis no R, para garantir que estamos selecionando corretamente os valores de interesse.
As variáveis disponíveis na base de dados, e suas unidades de medida são:
dados_brutos |>
distinct(`Variável`, `Unidade de Medida`)- 1
- Colunas que queremos buscar os valores distintos
Variável
1 Pessoas de 14 anos ou mais de idade
2 Coeficiente de variação - Pessoas de 14 anos ou mais de idade
3 Distribuição percentual das pessoas de 14 anos ou mais de idade
4 Coeficiente de variação - Distribuição percentual das pessoas de 14 anos ou mais de idade
Unidade de Medida
1 Mil pessoas
2 %
3 %
4 %Podemos observar, cada linha representa uma combinação de trimestre, unidade da federação e variável.
Outras perguntas relevantes ao analisar dados são:
- Qual é a pergunta que eu quero responder com esses dados?
- Quais são as variáveis que eu preciso para responder essa pergunta?
Padronizar nome das colunas
É uma boa prática padronizar o nome das colunas de um data frame. Assim evitamos problemas de codificação de caracteres (encoding), facilitamos a legibilidade do código e evitamos possíveis erros ao acessar as colunas.
O pacote janitor possui a função clean_names(), que padroniza os nomes das colunas de um data frame. Ele substitui espaços por underline (_), remove caracteres especiais, e transforma o texto em minúsculo, garantindo maior consistência ao lidar com os dados. Isso evita erros ao acessar colunas.
names(dados_brutos)- 1
- Checar o nome das colunas da base de dados
[1] "Nível Territorial (Código)"
[2] "Nível Territorial"
[3] "Unidade de Medida (Código)"
[4] "Unidade de Medida"
[5] "Valor"
[6] "Unidade da Federação (Código)"
[7] "Unidade da Federação"
[8] "Trimestre (Código)"
[9] "Trimestre"
[10] "Variável (Código)"
[11] "Variável"
[12] "Condição em relação à força de trabalho e condição de ocupação (Código)"
[13] "Condição em relação à força de trabalho e condição de ocupação" dados_renomeados <- janitor::clean_names(dados_brutos)
names(dados_renomeados)- 1
-
Limpar nomes das colunas da base de dados, e salvar em um novo objeto chamado
dados_renomeados - 2
- Checar o nome das colunas da base de dados renomeada
[1] "nivel_territorial_codigo"
[2] "nivel_territorial"
[3] "unidade_de_medida_codigo"
[4] "unidade_de_medida"
[5] "valor"
[6] "unidade_da_federacao_codigo"
[7] "unidade_da_federacao"
[8] "trimestre_codigo"
[9] "trimestre"
[10] "variavel_codigo"
[11] "variavel"
[12] "condicao_em_relacao_a_forca_de_trabalho_e_condicao_de_ocupacao_codigo"
[13] "condicao_em_relacao_a_forca_de_trabalho_e_condicao_de_ocupacao" Pipe - Encadeando funções
Nos exemplos anteriores, utilizamos uma função por vez, para facilitar a compreensão de cada etapa. No entanto, à medida que nos familiarizamos com as funções, podemos encadear várias delas em um único fluxo de código usando o operador pipe (%>% ou |>). Isso torna o código mais conciso e elimina a criação de objetos intermediários desnecessários.
Porém, é importante ter cuidado para não criar sequências muito longas e difíceis de entender.
Filtrando linhas (filter())
Para responder à pergunta norteadora, não precisamos de todas as variáveis presentes na base de dados. Podemos filtrar as linhas que são relevantes para a análise, escolhendo as variáveis de interesse.
Nesse caso, podemos filtrar os dados onde a variável é igual à "Pessoas de 14 anos ou mais de idade".
dados_filtrados <- dados_renomeados |>
filter(variavel == "Pessoas de 14 anos ou mais de idade")Para verificar se o filtro foi feito corretamente, podemos checar o número de linhas de cada base de dados:
nrow(dados_renomeados)[1] 27000nrow(dados_filtrados)[1] 6750Podemos verificar também os valores distintos para as colunas variavel e unidade_de_medida na base de dados dados_filtrados:
dados_filtrados |>
distinct(variavel, unidade_de_medida) variavel unidade_de_medida
1 Pessoas de 14 anos ou mais de idade Mil pessoasAgora sabemos que a base de dados dados_filtrados contém apenas dados sobre a variável "Pessoas de 14 anos ou mais de idade", e que a unidade de medida da coluna valor é mil pessoas.
Várias formas de filtrar as linhas
Como citamos anteriormente, em algumas situações existem várias formas diferentes de realizar uma tarefa.
No caso da função filter(), podemos utilizar diferentes operadores lógicos ou funções auxiliares para fazer filtros.
Os exemplos abaixo podem ser úteis para consulta futura!
Para esses exemplos, vamos utilizar a tabela starwars do pacote dplyr. Nessa tabela, cada linha representa um personagem de Star Wars, e as colunas representam diferentes características desses personagens.
Exemplos de operadores lógicos:
| Operador | Descrição | Exemplo | Interpretação |
|---|---|---|---|
== |
Igual à | species == "Human" |
Todas as linhas cuja espécie é “Human” |
!= |
Diferente de | species != "Human" |
Todas as linhas cuja espécie não é “Human” |
> |
Maior que | height > 180 |
Todas as linhas cuja altura é maior que 180 |
>= |
Maior ou igual a | height >= 180 |
Todas as linhas cuja altura é maior ou igual a 180 |
< |
Menor que | height < 180 |
Todas as linhas cuja altura é menor que 180 |
<= |
Menor ou igual a | height <= 180 |
Todas as linhas cuja altura é menor ou igual a 180 |
%in% |
Está em um conjunto | species %in% c("Human", "Droid") |
Todas as linhas cuja espécie é “Human” ou “Droid” |
! |
Negação | !is.na(height) |
Todas as linhas cuja altura não é NA |
! e %in% |
Negação de um conjunto | !(species %in% c("Human", "Droid")) |
Todas as linhas cuja espécie não é “Human” ou “Droid” |
Exemplos de funções auxiliares:
| Função | Descrição | Exemplo | Interpretação |
|---|---|---|---|
str_detect() |
Detecta padrões em textos | str_detect(name, "Skywalker") |
Todas as linhas cujo nome contém “Skywalker” |
str_starts() |
Detecta padrões no início de textos | str_starts(name, "Luke") |
Todas as linhas cujo nome começa com “Luke” |
str_ends() |
Detecta padrões no final de textos | str_ends(name, "Vader") |
Todas as linhas cujo nome termina com “Vader” |
Selecionando colunas (select())
Algumas colunas não são relevantes para responder à pergunta norteadora. Podemos selecionar apenas as colunas que vamos utilizar através da função select():
dados_selecionados <-
dados_filtrados |>
select(
# colunas que queremos manter
unidade_da_federacao,
unidade_da_federacao_codigo,
trimestre,
trimestre_codigo,
condicao_em_relacao_a_forca_de_trabalho_e_condicao_de_ocupacao,
valor
)
glimpse(dados_selecionados)Rows: 6,750
Columns: 6
$ unidade_da_federacao <chr> "Rondôn…
$ unidade_da_federacao_codigo <chr> "11", "…
$ trimestre <chr> "1º tri…
$ trimestre_codigo <chr> "201201…
$ condicao_em_relacao_a_forca_de_trabalho_e_condicao_de_ocupacao <chr> "Total"…
$ valor <dbl> 1210, 7…
Várias formas de selecionar colunas
Os exemplos abaixo podem ser úteis para consulta futura!
Para esses exemplos, vamos utilizar a tabela starwars do pacote dplyr:
Exemplos de seleção de colunas:
| Operador | Descrição | Exemplo | Interpretação |
|---|---|---|---|
: |
Seleciona um intervalo de colunas | name:mass |
Todas as colunas entre name e mass |
c() |
Seleciona colunas específicas | c(name, height, mass) |
Apenas as colunas name, height e mass |
-c() |
Exclui colunas específicas | -c(name, height, mass) |
Todas as colunas, exceto name, height e mass |
Exemplos de funções auxiliares:
| Função | Descrição | Exemplo | Interpretação |
|---|---|---|---|
starts_with() |
Seleciona colunas que começam com um prefixo | starts_with("h") |
Todas as colunas que começam com “h” |
ends_with() |
Seleciona colunas que terminam com um sufixo | ends_with("color") |
Todas as colunas que terminam com “color” |
contains() |
Seleciona colunas que contêm um padrão | contains("e") |
Todas as colunas que contêm “e” |
Renomeando colunas (rename())
Podemos renomear colunas com a função rename(). Vamos renomear algumas colunas para facilitar o uso posteriormente:
dados_renomeados_2 <- dados_selecionados |>
rename(
# colunas que queremos renomear: novo_nome = nome_atual
condicao = condicao_em_relacao_a_forca_de_trabalho_e_condicao_de_ocupacao,
valor_mil_pessoas = valor,
uf = unidade_da_federacao,
uf_codigo = unidade_da_federacao_codigo
)
glimpse(dados_renomeados_2)Rows: 6,750
Columns: 6
$ uf <chr> "Rondônia", "Rondônia", "Rondônia", "Rondônia", "Ron…
$ uf_codigo <chr> "11", "11", "11", "11", "11", "11", "11", "11", "11"…
$ trimestre <chr> "1º trimestre 2012", "1º trimestre 2012", "1º trimes…
$ trimestre_codigo <chr> "201201", "201201", "201201", "201201", "201201", "2…
$ condicao <chr> "Total", "Força de trabalho", "Força de trabalho - o…
$ valor_mil_pessoas <dbl> 1210, 765, 703, 62, 446, 1217, 782, 733, 49, 434, 12…Transformando a estrutura da tabela (pivot_wider() e pivot_longer())
Ainda considerando nossa pergunta norteadora, queremos calcular a taxa de desocupação de cada estado e região do Brasil ao longo do tempo. Para isso, é mais fácil trabalhar com a tabela onde cada linha represente uma UF por trimestre, e as categorias da variável condicao sejam transformadas em colunas.
Para fazer essa transformação, podemos usar a função pivot_wider(), do pacote {tidyr}.
A função pivot_wider() é útil quando queremos reorganizar uma tabela, transformando variáveis categóricas em novas colunas. Essa estrutura facilita cálculos comparativos e análises entre as diferentes categorias.
Por exemplo, no formato atual (dados longos), temos uma linha para cada combinação de UF, trimestre e condição de ocupação. Ao usarmos pivot_wider(), vamos transformar a tabela para que cada linha represente uma UF por trimestre, e as diferentes condições de ocupação (empregado, desocupado, etc.) se tornem colunas.
dados_largos <- dados_renomeados_2 |>
tidyr::pivot_wider(
names_from = condicao,
values_from = valor_mil_pessoas,
names_prefix = "mil_pessoas_"
)- 1
-
names_from =: Nome da coluna de onde os nomes das novas colunas serão extraídos - 2
-
values_from =: Nome da coluna de onde os valores para preencher as novas colunas serão extraídos - 3
-
names_prefix =: Podemos adicionar um texto como prefixo. Nesse caso, isso é opcional, mas é útil para ficar claro qual é a unidade de medida das variáveis.
glimpse(dados_largos)Rows: 1,350
Columns: 9
$ uf <chr> "Rondônia", "Rondônia", "…
$ uf_codigo <chr> "11", "11", "11", "11", "…
$ trimestre <chr> "1º trimestre 2012", "2º …
$ trimestre_codigo <chr> "201201", "201202", "2012…
$ mil_pessoas_Total <dbl> 1210, 1217, 1226, 1219, 1…
$ `mil_pessoas_Força de trabalho` <dbl> 765, 782, 784, 805, 796, …
$ `mil_pessoas_Força de trabalho - ocupada` <dbl> 703, 733, 738, 762, 746, …
$ `mil_pessoas_Força de trabalho - desocupada` <dbl> 62, 49, 46, 42, 49, 39, 3…
$ `mil_pessoas_Fora da força de trabalho` <dbl> 446, 434, 441, 415, 437, …Agora temos uma tabela onde cada linha representa uma UF por trimestre, e as categorias da variável condicao se tornaram colunas. Porém agora temos colunas com nomes que estão com caracteres especiais, e podemos arrumar isso com a função clean_names().
dados_largos_renomeados <- janitor::clean_names(dados_largos)
glimpse(dados_largos_renomeados)Rows: 1,350
Columns: 9
$ uf <chr> "Rondônia", "Rondônia", "Rond…
$ uf_codigo <chr> "11", "11", "11", "11", "11",…
$ trimestre <chr> "1º trimestre 2012", "2º trim…
$ trimestre_codigo <chr> "201201", "201202", "201203",…
$ mil_pessoas_total <dbl> 1210, 1217, 1226, 1219, 1233,…
$ mil_pessoas_forca_de_trabalho <dbl> 765, 782, 784, 805, 796, 800,…
$ mil_pessoas_forca_de_trabalho_ocupada <dbl> 703, 733, 738, 762, 746, 761,…
$ mil_pessoas_forca_de_trabalho_desocupada <dbl> 62, 49, 46, 42, 49, 39, 36, 3…
$ mil_pessoas_fora_da_forca_de_trabalho <dbl> 446, 434, 441, 415, 437, 443,…As funções pivot_longer() e pivot_wider() são usadas para alternar entre dados ‘longos’ e ‘largos’. Normalmente, dados longos são mais fáceis de visualizar, enquanto dados largos são melhores para realizar cálculos comparativos entre categorias. Para cada análise, sempre existe um formato mais apropriado a considerar.
Criando e transformando colunas (mutate())
Para criar novas colunas, ou transformar colunas que já existem, podemos usar a função mutate().
Alterando os tipos de variáveis
A variável uf_codigo está armazenada como valor numérico. No entanto, como não realizaremos operações matemáticas com esses valores, é mais apropriado transformá-los em fatores, o que facilita a análise e previne erros em cálculos futuros.
Existem várias funções para transformar variáveis de um tipo para outro, como as.factor(), as.character(), as.numeric(), as.Date(), etc.
dados_tipo <- dados_largos_renomeados |>
mutate(
# nova variável:
# nome_da_coluna = o que queremos calcular
uf_codigo = as.factor(uf_codigo)
)Calculando a taxa de desocupação
Para calcular a taxa de desocupação, precisamos criar uma nova variável representando a proporção de pessoas desocupadas em relação ao total de pessoas economicamente ativas.
dados_com_proporcao <- dados_tipo |>
mutate(
prop_desocupacao = mil_pessoas_forca_de_trabalho_desocupada / mil_pessoas_forca_de_trabalho,
perc_desocupacao = prop_desocupacao * 100
)- 1
-
Calculando a proporção da desocupação: para cada linha, vamos dividir o valor
mil_pessoas_forca_de_trabalho_desocupadapormil_pessoas_forca_de_trabalho. - 2
- Multiplicando por 100 para transformar em percentual.
Criando uma variável trimestre_inicio
Podemos criar uma nova variável chamada trimestre_inicio para representar a data de início de cada trimestre. Para isso, precisaremos criar algumas outras variáveis “auxiliares” a partir da variável trimestre_codigo: ano, trimestre_numero e trimestre_mes_inicio.
dados_com_trimestre <- dados_com_proporcao |>
mutate(
ano = stringr::str_sub(trimestre_codigo, 1, 4),
ano = as.numeric(ano),
trimestre_numero = stringr::str_sub(trimestre_codigo, 5, 6),
trimestre_numero = as.numeric(trimestre_numero),
trimestre_mes_inicio = case_when(
trimestre_numero == 1 ~ 1,
trimestre_numero == 2 ~ 4,
trimestre_numero == 3 ~ 7,
trimestre_numero == 4 ~ 10
),
trimestre_inicio = paste0(ano, "-", trimestre_mes_inicio, "-01"),
trimestre_inicio = as.Date(trimestre_inicio),
.after = trimestre_codigo
) |>
select(-trimestre_mes_inicio, -trimestre_numero)- 1
- Extrair os 4 primeiros caracteres do código do trimestre
- 2
-
Convertendo a coluna
anode texto para numérico - 3
- Extrair os 2 últimos caracteres do código do trimestre
- 4
-
Convertendo a coluna
trimestre_numerode texto para numérico - 5
- Criar variável com o mês de início do trimestre
- 6
- Criar variável com data de início do trimestre (neste momento, com tipo texto), colando os valores do mês e ano.
- 7
-
Convertendo a coluna
trimestre_iniciode texto para Data - 8
-
Queremos adicionar as colunas novas após a coluna
trimestre_codigo - 9
- Removendo colunas que não serão necessárias
Criando uma variável dummy
Uma variável dummy é uma variável binária que indica a presença ou ausência de algum atributo.
Podemos criar uma variável dummy para identificar os trimestres que ocorreram durante o período de emergência em saúde pública de importância nacional de COVID-19. Para isso, vamos criar uma nova variável chamada periodo_pandemia, que será 1 para os trimestres que ocorreram durante a pandemia, e 0 para os demais trimestres. A função que utilizaremos é a case_when() do pacote {dplyr}.
- Começo: Fevereiro de 2020
- Final: Abril de 2022
dados_com_dummy <- dados_com_trimestre |>
mutate(
periodo_pandemia = case_when(
trimestre_codigo %in% c("202001", "202002", "202003", "202004",
"202101", "202102", "202103", "202104",
"202201") ~ 1,
.default = 0
))- 1
-
Caso o
trimestre_codigosejam um dos listados dentro do vetor, queremos salvar o valor1na colunaperiodo_pandemia. - 2
-
O valor padrão é
0. Se nenhuma regra listada contemplar alguma linha, a coluna criada (periodo_pandemia) receberá o valor padrão (0). Ou seja, as linhas cujo período que não estão no vetor listado receberão o valor0.
Ordenando as linhas (arrange())
A base atual está ordada por trimestre e código da unidade da federação. Para facilitar a análise, podemos ordenar as linhas segundo a proporção de desocupação calculada no passo anterior, usando a função arrange():
dados_com_dummy |>
select(trimestre_codigo, uf, perc_desocupacao) |>
arrange(perc_desocupacao)- 1
- Selecionando colunas relevantes, para facilitar ver o resultado
- 2
-
Ordenar linhas usando a coluna
perc_desocupacao, de forma crescente
# A tibble: 1,350 × 3
trimestre_codigo uf perc_desocupacao
<chr> <chr> <dbl>
1 202303 Rondônia 2.34
2 202302 Rondônia 2.38
3 202303 Mato Grosso 2.42
4 201304 Santa Catarina 2.57
5 201204 Santa Catarina 2.69
6 201404 Santa Catarina 2.70
7 201402 Santa Catarina 2.83
8 201303 Santa Catarina 2.84
9 201403 Santa Catarina 2.95
10 202302 Mato Grosso 3.00
# ℹ 1,340 more rowsA função arrange() ordena, por padrão, de forma crescente. Podemos ordenar de forma decrescente, utilizando a função desc() junto à coluna que queremos ordenar de forma decrescente:
dados_com_dummy |>
select(trimestre_codigo, uf, perc_desocupacao) |>
arrange(desc(perc_desocupacao))- 1
- Selecionando colunas relevantes, para facilitar ver o resultado
- 2
-
Ordenar linhas usando a coluna
perc_desocupacao, de forma decrescente
# A tibble: 1,350 × 3
trimestre_codigo uf perc_desocupacao
<chr> <chr> <dbl>
1 202102 Pernambuco 21.8
2 201802 Amapá 21.7
3 202101 Bahia 21.7
4 201801 Amapá 21.6
5 202101 Pernambuco 21.4
6 202003 Bahia 21.1
7 202003 Sergipe 20.8
8 202004 Bahia 20.7
9 202101 Sergipe 20.7
10 202002 Bahia 20.5
# ℹ 1,340 more rowsNesse caso, as linhas ficaram ordenadas de forma decrescente, de acordo com a proporção de desocupação. Porém os trimestres não estão ordenados! A função arrange() permite que ordenemos por mais de uma coluna, e a ordem de prioridade é dada pela ordem em que as colunas são passadas para a função:
dados_ordenados <- dados_com_dummy |>
arrange(
# colunas que queremos usar ordenar
trimestre_codigo, desc(prop_desocupacao)
)
glimpse(dados_ordenados)Rows: 1,350
Columns: 14
$ uf <chr> "Amapá", "Bahia", "Rio Grande…
$ uf_codigo <fct> 16, 29, 24, 27, 13, 28, 25, 2…
$ trimestre <chr> "1º trimestre 2012", "1º trim…
$ trimestre_codigo <chr> "201201", "201201", "201201",…
$ ano <dbl> 2012, 2012, 2012, 2012, 2012,…
$ trimestre_inicio <date> 2012-01-01, 2012-01-01, 2012…
$ mil_pessoas_total <dbl> 487, 10986, 2540, 2383, 2463,…
$ mil_pessoas_forca_de_trabalho <dbl> 318, 6888, 1370, 1173, 1558, …
$ mil_pessoas_forca_de_trabalho_ocupada <dbl> 278, 6086, 1211, 1041, 1386, …
$ mil_pessoas_forca_de_trabalho_desocupada <dbl> 40, 802, 159, 133, 173, 99, 1…
$ mil_pessoas_fora_da_forca_de_trabalho <dbl> 170, 4098, 1170, 1210, 905, 6…
$ prop_desocupacao <dbl> 0.12578616, 0.11643438, 0.116…
$ perc_desocupacao <dbl> 12.578616, 11.643438, 11.6058…
$ periodo_pandemia <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…Agora temos a base de dados ordenada por trimestre, e dentro de cada trimestre, por proporção de desocupação (de forma descrecente).
Unindo duas bases de dados (left_join())
Unir duas tabelas é algo comum em análises de dados. Usamos operações do tipo join para combinar duas tabelas, utilizando uma ou mais colunas como “chave”. As colunas do tipo chave têm valores comuns nas duas tabelas e são usadas para identificar as linhas correspondentes entre elas.
O pacote {dplyr} fornece um conjunto de funções para realizar diferentes tipos de uniões, como left_join(), inner_join(), full_join(), entre outras.
A função left_join() é a mais frequentemente usada: ela mantém todas as linhas da primeira tabela e adiciona colunas da segunda tabela onde houver correspondência.
Exemplo 1: Introdutório
A base de dados que temos apresenta o nome e o código da UF, mas seria interessante ter a região, para futuramente usar essa variável em análises.
A base de dados importada abaixo é um arquivo .csv preparado com as informações necessárias:
uf_regiao <- readr::read_csv("https://raw.githubusercontent.com/ipeadata-lab/curso_r_intro_202409/refs/heads/main/dados/uf_regiao.csv")Rows: 27 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): uf_sigla, regiao
dbl (1): uf_codigo
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Vamos verificar a estrutura da base de dados uf_regiao:
glimpse(uf_regiao)Rows: 27
Columns: 3
$ uf_sigla <chr> "RO", "AC", "AM", "RR", "PA", "AP", "TO", "MA", "PI", "CE", …
$ uf_codigo <dbl> 11, 12, 13, 14, 15, 16, 17, 21, 22, 23, 24, 25, 26, 27, 28, …
$ regiao <chr> "Norte", "Norte", "Norte", "Norte", "Norte", "Norte", "Norte…Podemos tentar unir as tabelas, sem informar a chave. Quando não informamos a chave, a função buscará os nomes de colunas em comum para utilizar essas colunas como chave:
dados_ordenados |>
left_join(uf_regiao, by = "uf_codigo")Error in `left_join()`:
! Can't join `x$uf_codigo` with `y$uf_codigo` due to incompatible types.
ℹ `x$uf_codigo` is a <factor<48524>>.
ℹ `y$uf_codigo` is a <double>.No exemplo acima, a função left_join() tentou unir as tabelas com a coluna uf_codigo, presente nas duas tabelas.
Porém essas colunas apresentam tipos diferentes (fator e numérico). Precisamos deixá-las com o mesmo tipo para que a função left_join() consiga fazer a união corretamente. Vamos então transformar a coluna uf_codigo da tabela uf_regiao em fator:
uf_regiao_fct <- uf_regiao |>
mutate(uf_codigo = as.factor(uf_codigo)) Agora podemos unir as tabelas dados_ordenados e uf_regiao_fct:
dados_com_regiao <- dados_ordenados |>
left_join(uf_regiao_fct, by = "uf_codigo") |>
relocate(uf_sigla, regiao, .after = uf_codigo)- 1
-
Unindo a tabela
dados ordenadoseuf_regiao_fctusando como chave a colunauf_codigo. - 2
-
Mover as colunas
uf_siglaeregiaopara após a colunauf_codigo.
A nova tabela dados_com_regiao contém as colunas de uf_sigla e regiao, que foram adicionadas a partir da tabela uf_regiao_fct:
glimpse(dados_com_regiao)Rows: 1,350
Columns: 16
$ uf <chr> "Amapá", "Bahia", "Rio Grande…
$ uf_codigo <fct> 16, 29, 24, 27, 13, 28, 25, 2…
$ uf_sigla <chr> "AP", "BA", "RN", "AL", "AM",…
$ regiao <chr> "Norte", "Nordeste", "Nordest…
$ trimestre <chr> "1º trimestre 2012", "1º trim…
$ trimestre_codigo <chr> "201201", "201201", "201201",…
$ ano <dbl> 2012, 2012, 2012, 2012, 2012,…
$ trimestre_inicio <date> 2012-01-01, 2012-01-01, 2012…
$ mil_pessoas_total <dbl> 487, 10986, 2540, 2383, 2463,…
$ mil_pessoas_forca_de_trabalho <dbl> 318, 6888, 1370, 1173, 1558, …
$ mil_pessoas_forca_de_trabalho_ocupada <dbl> 278, 6086, 1211, 1041, 1386, …
$ mil_pessoas_forca_de_trabalho_desocupada <dbl> 40, 802, 159, 133, 173, 99, 1…
$ mil_pessoas_fora_da_forca_de_trabalho <dbl> 170, 4098, 1170, 1210, 905, 6…
$ prop_desocupacao <dbl> 0.12578616, 0.11643438, 0.116…
$ perc_desocupacao <dbl> 12.578616, 11.643438, 11.6058…
$ periodo_pandemia <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…Exemplo 2: Intermediário
Um exemplo comum de uso é quando temos dados por município ou estado, e desejamos visualizar esses dados em um mapa. Para isso, precisamos de informações geoespaciais, como a delimitação geográfica de cada município ou estado. Podemos usar o left_join() para combinar esses dados geoespaciais com os dados que queremos visualizar.
Vamos usar o pacote {geobr} para carregar as geometrias dos estados brasileiros.
Dica
O pacote {geobr} facilita o acesso a dados geoespaciais do Brasil, como estados, municípios e outras divisões administrativas. Ele é muito útil quando queremos fazer análises geoespaciais, já que oferece dados geográficos prontos para uso.
Podemos utilizar a função read_state() para carregar as geometrias dos estados brasileiros. Isso nos permite combinar essas geometrias com outros dados, como taxas de desocupação, e criar mapas que facilitam a visualização de padrões regionais.
Caso não tenha instalado anteriormente o pacote {geobr}, você pode instalar com o comando abaixo:
install.packages("geobr")geo_estados <- geobr::read_state(showProgress = FALSE)
glimpse(geo_estados)Rows: 27
Columns: 6
$ code_state <dbl> 11, 12, 13, 14, 15, 16, 17, 21, 22, 23, 24, 25, 26, 27, 2…
$ abbrev_state <chr> "RO", "AC", "AM", "RR", "PA", "AP", "TO", "MA", "PI", "CE…
$ name_state <chr> "Rondônia", "Acre", "Amazonas", "Roraima", "Pará", "Amapá…
$ code_region <dbl> 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, …
$ name_region <chr> "Norte", "Norte", "Norte", "Norte", "Norte", "Norte", "No…
$ geom <MULTIPOLYGON [°]> MULTIPOLYGON (((-63.32721 -..., MULTIPOLYGON…O left_join() é usado aqui para combinar os dados do SIDRA com os dados das delimitações das UFs. Cada linha do nosso dataset de desocupação será associada à respectiva geometria da UF, permitindo visualizarmos as proporções de desocupação por UF em um mapa. Esse tipo de operação é comum quando queremos identificar padrões regionais.
É importante garantir que as colunas usadas na combinação de tabelas (o argumento by do left_join()) tenham o mesmo tipo de dado. Podemos verificar o tipo de dado de cada coluna com a função class():
class(geo_estados$code_state)[1] "numeric"class(dados_com_regiao$uf_codigo)[1] "factor"Neste caso, as colunas que queremos usar como chave são de tipos diferentes (numérico e fator), O left_join() não conseguirá fazer a correspondência corretamente, e a função gerará um erro:
left_join(geo_estados, dados_com_regiao, by = join_by(code_state == uf_codigo))Error in `sf_column %in% names(g)`:
! Can't join `x$code_state` with `y$uf_codigo` due to incompatible
types.
ℹ `x$code_state` is a <double>.
ℹ `y$uf_codigo` is a <factor<48524>>.No exemplo, podemos transformar a coluna code_state em fator usando mutate(). Assim, garantimos que as colunas usadas no argumento by sejam do mesmo tipo e possam ser corretamente combinados.
dados_geo <- geo_estados |>
mutate(code_state = as.factor(code_state)) |>
left_join(dados_com_regiao, by = join_by(code_state == uf_codigo))
glimpse(dados_geo)Rows: 1,350
Columns: 21
$ code_state <fct> 11, 11, 11, 11, 11, 11, 11, 1…
$ abbrev_state <chr> "RO", "RO", "RO", "RO", "RO",…
$ name_state <chr> "Rondônia", "Rondônia", "Rond…
$ code_region <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ name_region <chr> "Norte", "Norte", "Norte", "N…
$ uf <chr> "Rondônia", "Rondônia", "Rond…
$ uf_sigla <chr> "RO", "RO", "RO", "RO", "RO",…
$ regiao <chr> "Norte", "Norte", "Norte", "N…
$ trimestre <chr> "1º trimestre 2012", "2º trim…
$ trimestre_codigo <chr> "201201", "201202", "201203",…
$ ano <dbl> 2012, 2012, 2012, 2012, 2013,…
$ trimestre_inicio <date> 2012-01-01, 2012-04-01, 2012…
$ mil_pessoas_total <dbl> 1210, 1217, 1226, 1219, 1233,…
$ mil_pessoas_forca_de_trabalho <dbl> 765, 782, 784, 805, 796, 800,…
$ mil_pessoas_forca_de_trabalho_ocupada <dbl> 703, 733, 738, 762, 746, 761,…
$ mil_pessoas_forca_de_trabalho_desocupada <dbl> 62, 49, 46, 42, 49, 39, 36, 3…
$ mil_pessoas_fora_da_forca_de_trabalho <dbl> 446, 434, 441, 415, 437, 443,…
$ prop_desocupacao <dbl> 0.08104575, 0.06265985, 0.058…
$ perc_desocupacao <dbl> 8.104575, 6.265985, 5.867347,…
$ periodo_pandemia <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ geom <MULTIPOLYGON [°]> MULTIPOLYGON (((…Agora temos uma base de dados que combina os dados do SIDRA com as geometrias dos estados brasileiros.
Combinar dados dessa forma nos permite fazer visualizações geoespaciais, como um mapa de calor das taxas de desocupação por estado. Isso facilita a identificação de padrões regionais, ajudando na interpretação dos dados.
Não falaremos nesse momento sobre como criar visualizações e mapas, pois isso será abordado em aulas futuras. Mas podemos adiantar um exemplo de como criar um mapa apresentando as proporções de desocupação por estado:
Código
library(ggplot2)
dados_geo |>
filter(trimestre_codigo == "202402") |>
ggplot() +
geom_sf(aes(fill = perc_desocupacao)) +
theme_light() +
scale_fill_viridis_c() +
labs(title = "Percentual de desocupação por UF no 2º trimestre de 2024",
fill = "Desocupação (%)") +
theme(legend.position = "bottom")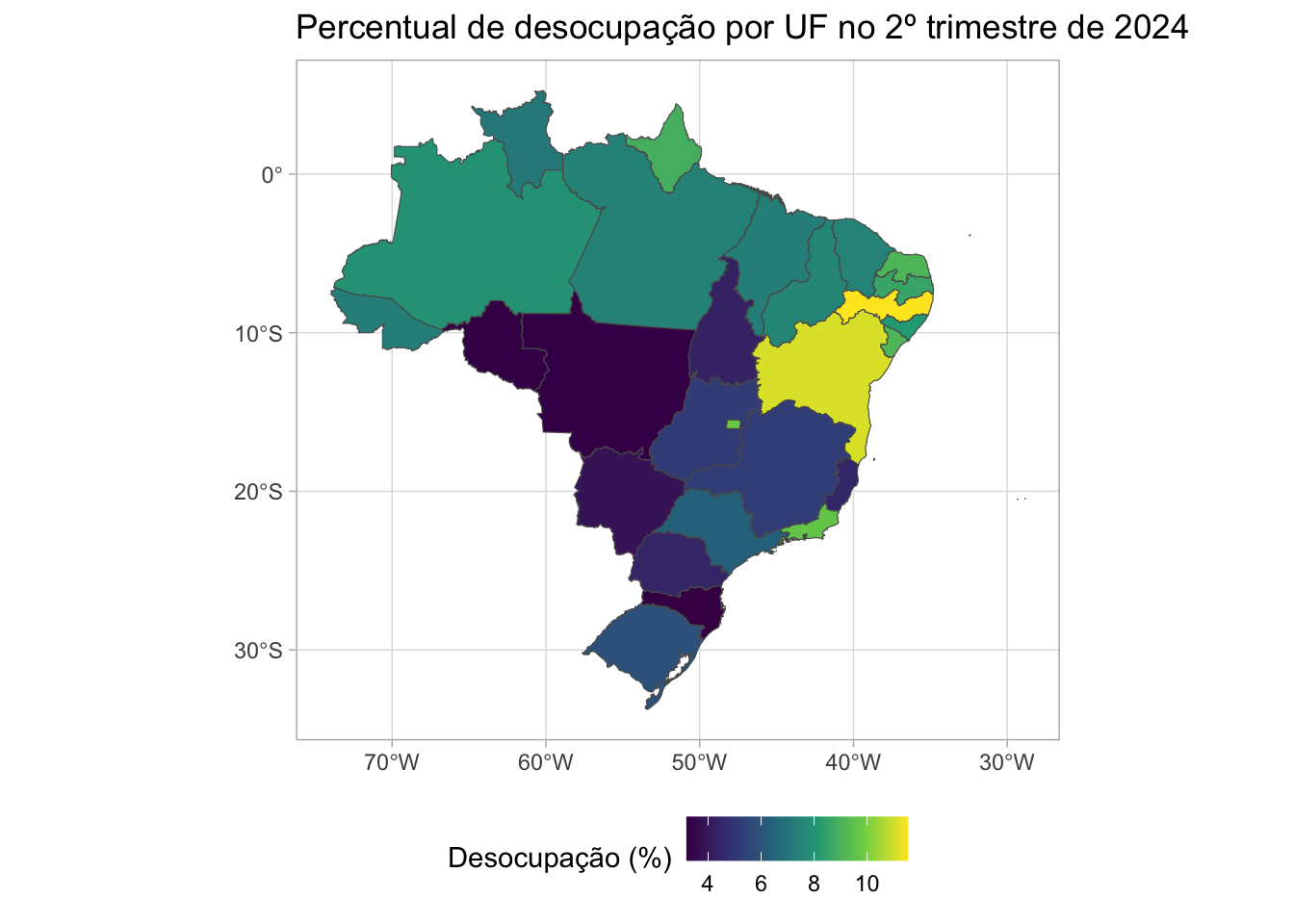
Salvando a base de dados preparada
Por fim, podemos salvar a base de dados preparada para usar nas próximas etapas. Assim não precisamos repetir todo o processo de limpeza e transformação de dados a cada vez que quisermos fazer uma análise.
É recomendável salvar a base de dados em um formato que preserve a estrutura dos dados, como .rds.
# Salvando os dados preparados
readr::write_rds(dados_com_regiao, "dados_output/sidra_4092_arrumado.rds")Exercícios sugeridos
Utilizando a base de dados que criamos nessa aula (com a taxa de desocupação calculada), responda as perguntas abaixo.
- Crie uma nova tabela com apenas as colunas
uf,trimestre,perc_desocupacaoeperiodo_pandemia.
Dica 1
O resultado esperado é:
# A tibble: 1,350 × 4
uf trimestre perc_desocupacao periodo_pandemia
<chr> <chr> <dbl> <dbl>
1 Amapá 1º trimestre 2012 12.6 0
2 Bahia 1º trimestre 2012 11.6 0
3 Rio Grande do Norte 1º trimestre 2012 11.6 0
4 Alagoas 1º trimestre 2012 11.3 0
5 Amazonas 1º trimestre 2012 11.1 0
6 Sergipe 1º trimestre 2012 10.5 0
7 Paraíba 1º trimestre 2012 10.0 0
8 Pernambuco 1º trimestre 2012 9.58 0
9 Acre 1º trimestre 2012 9.27 0
10 Distrito Federal 1º trimestre 2012 8.80 0
# ℹ 1,340 more rows- Qual foi a combinação de Estado/Trimestre que teve a maior taxa de desocupação…
- Durante a pandemia?
- Fora do período de pandemia?
Dica 1
Para cada pergunta (durante ou fora do período de pandemia), precisamos fazer dois filtros:
- Filtrar as linhas que correspondem ao período de pandemia (ou fora dele)
- Filtrar a linha com a maior taxa de desocupação
Dica 2
Para buscar o maior valor de uma coluna, podemos usar a função max().
Por exemplo: o código abaixo retorna a linha com o personagem de Star Wars com o maior valor de massa (mass). Nesse caso, precisamos usar o argumento na.rm = TRUE para ignorar valores NA, pois a coluna mass tem valores faltantes.
starwars |>
filter(mass == max(mass, na.rm = TRUE))# A tibble: 1 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Jabba De… 175 1358 <NA> green-tan… orange 600 herm… mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Dica 3
O resultado esperado é:
| uf | trimestre | perc_desocupacao | periodo_pandemia |
|---|---|---|---|
| Pernambuco | 2º trimestre 2021 | 21.7527 | 1 |
- Considerando o trimestre mais recente disponível, qual é o estado com a maior taxa de desocupação? E a maior?
Dica 1
Para cada pergunta (durante ou fora do período de pandemia), precisamos fazer dois filtros:
- Filtrar as linhas que correspondem ao trimestre mais recente
- Filtrar a linha com a maior OU menor taxa de desocupação
Dica 2
Podemos fazer o filtro usando o operador OU (|), para filtrar as linhas que correspondem ao estado com a maior OU menor taxa de desocupação.
Por exemplo: o código abaixo retorna a linha com o personagem de Star Wars com o maior e o menor valor de massa (mass). Nesse caso, precisamos usar o argumento na.rm = TRUE para ignorar valores NA, pois a coluna mass tem valores faltantes.
starwars |>
filter(mass == max(mass, na.rm = TRUE) | mass == min(mass, na.rm = TRUE))# A tibble: 2 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Jabba De… 175 1358 <NA> green-tan… orange 600 herm… mascu…
2 Ratts Ty… 79 15 none grey, blue unknown NA male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Dica 3
O resultado esperado é:
| uf | trimestre | perc_desocupacao |
|---|---|---|
| Pernambuco | 2º trimestre 2024 | 11.533052 |
| Santa Catarina | 2º trimestre 2024 | 3.190735 |
- Considerando o trimestre mais recente disponível, quais são os 5 estados com as maiores taxas de desocupação?
Dica 1
A função head() retorna as primeiras linhas de um data frame. Podemos usar essa função para retornar as primeiras linhas de um data frame ordenado, usando o número de linhas desejadas como argumento:
# A tibble: 5 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Jabba De… 175 1358 <NA> green-tan… orange 600 herm… mascu…
2 Grievous 216 159 none brown, wh… green, y… NA male mascu…
3 IG-88 200 140 none metal red 15 none mascu…
4 Darth Va… 202 136 none white yellow 41.9 male mascu…
5 Tarfful 234 136 brown brown blue NA male mascu…
# ℹ 5 more variables: homeworld <chr>, species <chr>, films <list>,
# vehicles <list>, starships <list>
Dica 2
O resultado esperado é:
| uf | trimestre | perc_desocupacao |
|---|---|---|
| Pernambuco | 2º trimestre 2024 | 11.533052 |
| Bahia | 2º trimestre 2024 | 11.098283 |
| Distrito Federal | 2º trimestre 2024 | 9.742441 |
| Rio de Janeiro | 2º trimestre 2024 | 9.644113 |
| Sergipe | 2º trimestre 2024 | 9.131602 |
- Utilizando a função
tidyr::pivot_wider(), como podemos criar uma tabela onde cada linha apresente dados de um estado, e cada trimestre esteja em uma coluna preenchida com os valores de percentual de desocupação?
Veja o exemplo abaixo:
| uf | 1º trimestre 2012 | 2º trimestre 2012 | 3º trimestre 2012 | 4º trimestre 2012 | 1º trimestre 2013 | 2º trimestre 2013 | 3º trimestre 2013 | 4º trimestre 2013 | 1º trimestre 2014 | 2º trimestre 2014 | 3º trimestre 2014 | 4º trimestre 2014 | 1º trimestre 2015 | 2º trimestre 2015 | 3º trimestre 2015 | 4º trimestre 2015 | 1º trimestre 2016 | 2º trimestre 2016 | 3º trimestre 2016 | 4º trimestre 2016 | 1º trimestre 2017 | 2º trimestre 2017 | 3º trimestre 2017 | 4º trimestre 2017 | 1º trimestre 2018 | 2º trimestre 2018 | 3º trimestre 2018 | 4º trimestre 2018 | 1º trimestre 2019 | 2º trimestre 2019 | 3º trimestre 2019 | 4º trimestre 2019 | 1º trimestre 2020 | 2º trimestre 2020 | 3º trimestre 2020 | 4º trimestre 2020 | 1º trimestre 2021 | 2º trimestre 2021 | 3º trimestre 2021 | 4º trimestre 2021 | 1º trimestre 2022 | 2º trimestre 2022 | 3º trimestre 2022 | 4º trimestre 2022 | 1º trimestre 2023 | 2º trimestre 2023 | 3º trimestre 2023 | 4º trimestre 2023 | 1º trimestre 2024 | 2º trimestre 2024 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Amapá | 12.578616 | 14.603175 | 14.285714 | 12.158055 | 11.671924 | 14.461538 | 10.942249 | 9.253731 | 11.242604 | 9.970674 | 10.632184 | 9.565217 | 9.821429 | 10.294118 | 11.849711 | 13.068182 | 14.619883 | 16.000000 | 15.142857 | 16.991643 | 18.836565 | 17.451524 | 16.986301 | 19.073570 | 21.621622 | 21.739130 | 18.324607 | 19.893899 | 20.365535 | 17.164179 | 16.879795 | 15.776081 | 17.268041 | 11.370262 | 15.297450 | 15.902965 | 15.217391 | 16.230366 | 17.487685 | 17.422434 | 14.175258 | 11.401425 | 10.843374 | 13.225058 | 12.206573 | 12.442396 | 12.471655 | 14.187643 | 10.854503 | 8.878505 |
| Bahia | 11.643438 | 11.392588 | 10.794883 | 10.851468 | 13.431301 | 11.878128 | 10.754579 | 9.102656 | 11.658363 | 10.172635 | 9.846110 | 9.788841 | 11.440914 | 12.825124 | 13.014077 | 12.397155 | 15.742825 | 15.627210 | 16.070406 | 16.763745 | 18.633186 | 17.596811 | 16.813520 | 15.124606 | 18.098115 | 16.778621 | 16.389953 | 17.619454 | 18.478722 | 17.469710 | 16.924167 | 16.531512 | 18.825025 | 20.506122 | 21.149536 | 20.743877 | 21.723411 | 20.158451 | 18.727222 | 17.332961 | 17.570987 | 15.460020 | 15.112994 | 13.505788 | 14.432990 | 13.385035 | 13.317328 | 12.656785 | 14.039584 | 11.098283 |
| Rio Grande do Norte | 11.605839 | 11.355816 | 11.469780 | 11.602210 | 12.159329 | 10.901468 | 10.143934 | 9.785523 | 11.846459 | 11.768617 | 10.646900 | 10.483871 | 11.597084 | 11.776316 | 12.805663 | 12.328767 | 14.494681 | 13.588390 | 14.248194 | 14.700066 | 16.446499 | 15.841584 | 13.879709 | 12.408759 | 15.085639 | 13.280736 | 12.993631 | 13.630491 | 14.060447 | 12.662338 | 13.609851 | 12.972621 | 15.591054 | 15.300146 | 17.864769 | 15.593895 | 15.491101 | 16.263441 | 14.713715 | 12.630208 | 14.140127 | 12.012780 | 10.482315 | 9.960938 | 12.145749 | 10.263336 | 10.086840 | 8.289125 | 9.626719 | 9.085173 |
| Alagoas | 11.338448 | 11.688312 | 11.589404 | 11.182623 | 12.289157 | 10.834671 | 10.572337 | 9.397590 | 9.789644 | 9.740260 | 9.802371 | 9.479409 | 11.199365 | 11.920000 | 10.933759 | 11.480602 | 12.943962 | 14.118565 | 14.948859 | 14.927769 | 17.714286 | 18.004866 | 16.055420 | 15.739949 | 17.991266 | 17.672791 | 17.328825 | 16.177703 | 16.139767 | 14.927769 | 15.640194 | 13.830679 | 16.666667 | 18.255396 | 20.284698 | 20.408163 | 20.216886 | 19.198791 | 17.047971 | 14.510364 | 14.136126 | 11.111111 | 10.109890 | 9.302326 | 10.589113 | 9.696521 | 8.983800 | 8.879185 | 9.882870 | 8.147080 |
| Amazonas | 11.103979 | 9.055877 | 9.508615 | 8.348910 | 10.357583 | 10.287814 | 8.405978 | 7.715860 | 8.333333 | 8.441158 | 6.816798 | 7.891492 | 9.512195 | 9.685230 | 10.279263 | 9.282700 | 12.923977 | 13.442995 | 13.759355 | 15.049390 | 18.024554 | 15.607581 | 16.248575 | 13.592233 | 13.991081 | 14.334086 | 13.245033 | 14.558342 | 16.052061 | 14.043455 | 13.533439 | 13.038906 | 14.622642 | 16.619075 | 16.856987 | 15.708200 | 17.602996 | 15.792208 | 13.428281 | 13.104524 | 13.001524 | 10.420945 | 9.346272 | 10.015330 | 10.509721 | 9.669080 | 9.555442 | 8.808554 | 9.792746 | 7.909605 |
| Sergipe | 10.454066 | 10.950413 | 10.627530 | 9.667969 | 11.694747 | 11.374876 | 10.147783 | 8.791209 | 9.542744 | 9.809810 | 9.171598 | 8.994197 | 8.733205 | 9.152216 | 8.771930 | 10.187933 | 11.534702 | 12.925170 | 14.424951 | 15.204678 | 16.314199 | 14.215686 | 13.833992 | 13.601533 | 17.198068 | 16.992188 | 17.647059 | 15.117371 | 15.522107 | 15.349682 | 14.781022 | 14.933333 | 15.789474 | 20.377734 | 20.808081 | 18.276515 | 20.695971 | 19.316081 | 17.059891 | 14.460999 | 14.955752 | 12.750455 | 12.129630 | 11.952555 | 11.825922 | 10.331754 | 9.796673 | 11.204482 | 9.982014 | 9.131602 |
| Paraíba | 10.017996 | 9.410363 | 8.609272 | 9.168185 | 9.593200 | 9.004739 | 8.578284 | 8.490566 | 9.352941 | 8.888889 | 9.340339 | 8.172796 | 9.335624 | 9.315699 | 10.502283 | 9.716599 | 10.251904 | 11.018463 | 13.048707 | 12.154031 | 13.413897 | 11.565836 | 10.883558 | 10.227937 | 11.892209 | 11.071849 | 10.976314 | 11.239861 | 11.223278 | 12.183637 | 11.359623 | 12.153392 | 13.875598 | 13.216453 | 17.305152 | 15.727554 | 16.149068 | 15.448188 | 14.464621 | 13.008130 | 14.328358 | 12.214200 | 10.867052 | 10.301954 | 11.117717 | 10.394265 | 9.273479 | 9.584296 | 9.868044 | 8.579546 |
| Pernambuco | 9.579618 | 8.298539 | 9.382903 | 9.200410 | 10.681877 | 9.714286 | 8.493221 | 7.420495 | 8.828045 | 8.015171 | 8.466934 | 7.709581 | 8.204489 | 9.206040 | 11.309100 | 11.141038 | 13.401559 | 14.247312 | 15.459298 | 15.942029 | 17.331022 | 19.024271 | 18.064673 | 16.990641 | 17.955997 | 17.116477 | 17.009700 | 15.641932 | 16.303584 | 16.080283 | 15.994305 | 14.151165 | 14.801357 | 15.363206 | 19.276781 | 19.394394 | 21.402748 | 21.752701 | 19.282297 | 17.144890 | 17.015276 | 13.555347 | 13.924344 | 12.315271 | 14.078238 | 14.184397 | 13.207996 | 11.932892 | 12.408587 | 11.533052 |
| Acre | 9.265176 | 9.118541 | 7.692308 | 8.132530 | 10.909091 | 9.451220 | 8.841463 | 7.055215 | 8.181818 | 9.638554 | 7.164179 | 6.287425 | 8.985507 | 8.849557 | 9.037901 | 7.848837 | 8.771930 | 11.212121 | 12.074303 | 11.818182 | 15.915916 | 15.072464 | 13.793103 | 12.429379 | 14.763231 | 13.675214 | 13.370473 | 13.461538 | 18.207283 | 13.687151 | 13.202247 | 13.881020 | 13.823529 | 14.454277 | 17.365270 | 15.921788 | 18.032787 | 16.452442 | 13.756614 | 13.385827 | 14.854111 | 11.904762 | 10.000000 | 9.887006 | 9.667674 | 9.422492 | 6.176471 | 6.567164 | 8.797654 | 7.303371 |
| Distrito Federal | 8.802817 | 8.492569 | 8.686588 | 8.847737 | 9.679618 | 9.200806 | 8.984375 | 8.514852 | 9.066667 | 9.151194 | 8.958195 | 8.766015 | 10.868125 | 9.760956 | 10.390470 | 9.815547 | 11.292428 | 11.023622 | 12.134689 | 14.043887 | 14.294593 | 13.329161 | 12.333966 | 13.341724 | 14.055728 | 12.292563 | 12.658228 | 12.040939 | 14.192009 | 13.797170 | 13.207547 | 12.544803 | 13.595707 | 15.592783 | 15.686274 | 14.461538 | 14.957781 | 14.311815 | 14.520870 | 12.110727 | 12.536106 | 11.523328 | 10.932297 | 10.253583 | 11.977716 | 8.749299 | 8.858603 | 9.664805 | 9.566185 | 9.742441 |
| Roraima | 8.648649 | 5.851064 | 7.291667 | 8.163265 | 8.854167 | 8.542714 | 8.212560 | 6.930693 | 7.582938 | 5.633803 | 6.603774 | 6.278027 | 9.174312 | 7.798165 | 9.589041 | 8.144796 | 8.144796 | 8.144796 | 9.767442 | 9.523810 | 10.280374 | 10.762332 | 9.333333 | 9.829060 | 10.504202 | 11.666667 | 13.469388 | 14.229249 | 15.175097 | 15.261044 | 14.859438 | 14.843750 | 16.470588 | 17.030568 | 19.067797 | 14.634146 | 14.285714 | 13.962264 | 10.727969 | 9.160305 | 8.695652 | 6.130268 | 4.942966 | 4.494382 | 6.934307 | 5.019305 | 7.720588 | 7.067138 | 7.500000 | 7.142857 |
| Rio de Janeiro | 8.561516 | 7.507360 | 7.484587 | 6.870698 | 7.328750 | 7.034805 | 6.918932 | 6.234476 | 6.752609 | 6.539980 | 6.207744 | 5.840227 | 6.605052 | 7.289018 | 8.346381 | 8.672119 | 10.176196 | 11.564139 | 12.256301 | 13.618220 | 14.666512 | 15.829894 | 14.629988 | 15.254428 | 15.132623 | 15.506329 | 14.706214 | 14.959659 | 15.435943 | 15.254048 | 14.601622 | 13.832149 | 14.683516 | 16.757764 | 19.336130 | 19.629187 | 19.640519 | 17.866787 | 15.904261 | 14.195758 | 14.915445 | 12.625698 | 12.308205 | 11.432706 | 11.645910 | 11.257539 | 10.908078 | 10.035328 | 10.321730 | 9.644113 |
| Tocantins | 8.409786 | 7.774390 | 7.208589 | 7.726597 | 9.312977 | 8.194234 | 6.298003 | 6.534954 | 8.567208 | 7.794118 | 7.647908 | 6.351551 | 8.888889 | 7.669617 | 9.305761 | 8.997050 | 10.755814 | 11.206897 | 10.882353 | 13.199426 | 12.608696 | 11.600587 | 11.922504 | 10.601719 | 11.079546 | 11.328671 | 9.817672 | 10.519126 | 12.500000 | 11.538462 | 10.714286 | 9.266943 | 11.538462 | 12.735166 | 12.518629 | 11.265647 | 17.127800 | 15.875170 | 10.817942 | 9.647979 | 9.208820 | 5.491699 | 5.660377 | 5.163728 | 6.947891 | 6.557377 | 5.323194 | 5.721393 | 5.992509 | 4.305043 |
| Rondônia | 8.104575 | 6.265985 | 5.867347 | 5.217391 | 6.155779 | 4.875000 | 4.591837 | 4.961832 | 5.044136 | 4.113111 | 4.198473 | 3.615960 | 4.551201 | 4.961832 | 6.691450 | 6.495098 | 7.635468 | 7.923169 | 8.578431 | 8.091787 | 8.178439 | 9.199522 | 8.185053 | 7.602339 | 10.514019 | 8.233890 | 8.901734 | 9.132420 | 9.070034 | 6.912442 | 8.352144 | 8.154020 | 8.520179 | 11.057108 | 11.764706 | 11.124260 | 11.360947 | 9.907834 | 7.812500 | 6.877729 | 6.919643 | 5.816555 | 3.932584 | 3.037383 | 3.159174 | 2.378121 | 2.344666 | 3.814064 | 3.657143 | 3.295454 |
| Pará | 8.004744 | 7.889546 | 7.224443 | 6.862745 | 7.880959 | 7.711512 | 7.771876 | 6.123017 | 7.785088 | 7.156567 | 7.234507 | 7.109525 | 9.371643 | 9.180942 | 8.572936 | 8.764104 | 10.181055 | 10.989888 | 11.182623 | 12.895570 | 13.954741 | 11.503719 | 11.200415 | 10.739979 | 12.272367 | 11.310920 | 11.047420 | 10.269012 | 11.600626 | 11.331076 | 11.340996 | 9.275960 | 10.764068 | 9.306261 | 11.144091 | 10.940349 | 13.865323 | 13.529564 | 11.863137 | 10.970258 | 12.148619 | 9.137179 | 8.851043 | 8.232503 | 9.831666 | 8.574205 | 8.018411 | 7.801755 | 8.506525 | 7.437425 |
| Maranhão | 7.938258 | 9.203347 | 7.745204 | 7.596330 | 9.513355 | 9.437454 | 7.487832 | 5.592105 | 6.437768 | 7.196295 | 6.810926 | 7.165549 | 9.030451 | 8.950509 | 8.587258 | 8.388444 | 11.099549 | 12.030347 | 12.080537 | 13.215209 | 15.154827 | 14.748603 | 14.533623 | 13.412375 | 15.777695 | 14.472671 | 13.986280 | 14.296492 | 16.557314 | 14.786585 | 14.382530 | 12.406015 | 16.301059 | 16.456229 | 17.302905 | 14.588329 | 17.377812 | 17.503748 | 15.003668 | 13.357798 | 12.882748 | 10.770893 | 9.671788 | 8.353982 | 9.917355 | 8.837209 | 6.729428 | 7.152826 | 8.445089 | 7.291300 |
| Minas Gerais | 7.899160 | 7.254977 | 6.433647 | 6.298300 | 7.524059 | 7.034509 | 6.339235 | 5.781954 | 7.100422 | 6.923517 | 6.935808 | 6.332730 | 8.332543 | 7.960292 | 8.788270 | 9.396097 | 11.304187 | 11.035995 | 11.278539 | 11.210680 | 13.773001 | 12.198646 | 12.301195 | 10.680741 | 12.669643 | 10.879589 | 9.796099 | 9.738061 | 11.240275 | 9.623321 | 10.006096 | 9.580316 | 11.695906 | 13.181688 | 13.606789 | 12.461752 | 13.918845 | 12.621183 | 10.694714 | 9.434794 | 9.314155 | 7.238395 | 6.324457 | 5.776431 | 6.799823 | 5.807365 | 5.976096 | 5.686206 | 6.299282 | 5.278592 |
| São Paulo | 7.820856 | 7.539857 | 6.965958 | 6.772246 | 7.803669 | 7.502153 | 7.429088 | 6.615699 | 7.326612 | 7.144396 | 7.331264 | 7.228196 | 8.607079 | 9.191906 | 9.787791 | 10.252569 | 12.196327 | 12.246484 | 12.873347 | 12.493411 | 14.366919 | 13.609349 | 13.323027 | 12.846258 | 14.131718 | 13.768002 | 13.264152 | 12.594183 | 13.587798 | 12.922038 | 12.147813 | 11.583234 | 12.282685 | 13.924865 | 15.432916 | 14.802442 | 14.656620 | 14.524827 | 13.375498 | 11.129460 | 10.794840 | 9.174872 | 8.630588 | 7.670323 | 8.472944 | 7.826522 | 7.144776 | 6.857903 | 7.384321 | 6.376171 |
| Piauí | 7.654494 | 7.072829 | 6.228374 | 7.019959 | 8.430432 | 7.525424 | 7.496561 | 7.003367 | 7.095926 | 7.142857 | 6.225166 | 6.024096 | 7.836571 | 7.702436 | 7.758054 | 7.348029 | 9.655638 | 10.075914 | 9.616725 | 8.903134 | 12.811388 | 13.690062 | 12.249135 | 13.449477 | 13.347609 | 13.566434 | 12.517194 | 12.388775 | 12.947658 | 13.019768 | 12.938882 | 13.306720 | 14.086471 | 13.355317 | 13.191812 | 12.225476 | 15.153681 | 15.357887 | 11.922812 | 11.849315 | 12.309820 | 9.407666 | 9.242529 | 9.449929 | 11.126962 | 9.708029 | 9.847434 | 10.655148 | 10.007047 | 7.535211 |
| Espírito Santo | 7.651150 | 7.243356 | 6.887623 | 6.711066 | 7.810894 | 7.707911 | 7.207207 | 5.940083 | 6.398349 | 6.605223 | 5.861182 | 6.197917 | 7.094769 | 6.775344 | 8.311955 | 9.267793 | 11.156393 | 11.652436 | 12.914752 | 13.787954 | 14.679359 | 13.465251 | 13.136602 | 11.756168 | 12.729026 | 12.238095 | 11.346516 | 10.377358 | 12.349118 | 10.990009 | 10.707721 | 10.436782 | 11.276102 | 12.611276 | 14.189837 | 13.434969 | 13.113207 | 11.583924 | 9.939619 | 9.830041 | 9.206799 | 7.985314 | 7.255083 | 7.249071 | 6.943788 | 6.343985 | 5.563282 | 5.238971 | 5.912007 | 4.502046 |
| Mato Grosso do Sul | 7.547170 | 7.063492 | 4.983923 | 5.003971 | 4.811548 | 4.937304 | 4.432348 | 4.541895 | 4.746835 | 3.897116 | 4.098995 | 3.852080 | 6.298003 | 6.365031 | 6.334842 | 6.015038 | 7.847534 | 7.043287 | 7.714916 | 8.194344 | 9.905317 | 8.966016 | 8.040936 | 7.415407 | 8.528785 | 7.703281 | 7.332402 | 7.023644 | 9.573725 | 8.418891 | 7.708333 | 6.703911 | 7.894737 | 11.680482 | 11.813394 | 9.527326 | 10.587382 | 9.822064 | 7.621083 | 6.411150 | 6.490728 | 5.197505 | 5.112474 | 3.346720 | 4.856953 | 4.089710 | 4.008016 | 4.002668 | 4.983165 | 3.815261 |
| Ceará | 7.321619 | 8.186667 | 8.112493 | 7.552870 | 8.944641 | 8.531693 | 7.303974 | 6.933826 | 7.948583 | 7.568688 | 7.558442 | 6.647168 | 8.101604 | 8.920559 | 9.718603 | 9.064559 | 10.907156 | 11.589404 | 13.261923 | 12.602041 | 14.448381 | 13.329954 | 11.959799 | 11.203117 | 12.942613 | 11.812577 | 10.729821 | 10.181818 | 11.547792 | 11.025703 | 11.424474 | 10.338301 | 12.382332 | 12.302138 | 14.258029 | 14.463453 | 15.111232 | 15.073145 | 12.449393 | 11.083060 | 11.017618 | 10.341366 | 8.564295 | 7.786070 | 9.548255 | 8.599132 | 9.178864 | 8.718331 | 8.646713 | 7.480214 |
| Mato Grosso | 6.577267 | 5.766793 | 5.253165 | 4.785894 | 5.813234 | 4.542664 | 3.941783 | 3.737745 | 4.482132 | 3.995157 | 3.862402 | 4.070474 | 5.801435 | 6.291591 | 6.740196 | 5.768063 | 9.227986 | 9.988249 | 9.080048 | 9.627880 | 10.605153 | 8.716418 | 9.485252 | 7.334109 | 9.474292 | 8.599089 | 6.768190 | 6.904232 | 9.160724 | 8.310847 | 7.978437 | 6.428571 | 8.577633 | 10.230467 | 10.168539 | 10.642896 | 10.154525 | 9.085873 | 6.640841 | 5.937328 | 5.321508 | 4.408602 | 3.848238 | 3.504929 | 4.528096 | 3.002183 | 2.423263 | 3.911477 | 3.751285 | 3.282828 |
| Goiás | 6.337372 | 5.272783 | 4.986150 | 5.145482 | 6.807229 | 5.793145 | 5.236232 | 3.950913 | 5.725420 | 5.367734 | 5.202483 | 5.154339 | 7.034442 | 7.452340 | 7.384883 | 7.814302 | 10.202915 | 10.253521 | 10.652921 | 11.341943 | 12.783852 | 11.016949 | 9.333693 | 9.432934 | 10.372992 | 9.512129 | 9.011707 | 8.294931 | 10.850440 | 10.600425 | 10.943592 | 10.557873 | 11.527224 | 12.987753 | 13.527252 | 12.737430 | 13.862201 | 12.418122 | 10.013351 | 8.755274 | 8.860760 | 6.801008 | 6.123973 | 6.637733 | 6.710229 | 6.158065 | 5.910107 | 5.593719 | 6.082904 | 5.167769 |
| Paraná | 5.638894 | 5.347972 | 4.669604 | 4.473406 | 4.941300 | 4.597502 | 4.246836 | 3.784722 | 4.186935 | 4.247971 | 4.163799 | 3.751527 | 5.385152 | 6.226285 | 6.229565 | 5.874340 | 8.162580 | 8.230730 | 8.579681 | 8.158116 | 10.386352 | 8.958716 | 8.498156 | 8.252912 | 9.660792 | 9.089393 | 8.726610 | 7.889969 | 9.019351 | 9.124980 | 9.057032 | 7.350539 | 8.003287 | 9.618270 | 10.545206 | 10.066225 | 9.427109 | 9.036861 | 7.971014 | 6.961114 | 6.851972 | 6.067489 | 5.255591 | 5.130687 | 5.391276 | 4.863025 | 4.621849 | 4.704753 | 4.821570 | 4.439141 |
| Rio Grande do Sul | 5.342847 | 5.077453 | 4.655590 | 4.386566 | 5.411804 | 4.628378 | 4.905408 | 4.726119 | 5.438979 | 5.033784 | 5.318251 | 4.604486 | 5.807201 | 6.056056 | 6.990324 | 6.679764 | 7.584407 | 8.913649 | 8.382546 | 8.423291 | 9.268293 | 8.571896 | 8.172920 | 8.080808 | 8.586526 | 8.440153 | 8.272546 | 7.482437 | 8.046723 | 8.267780 | 8.934321 | 7.252152 | 8.536389 | 9.679642 | 10.523551 | 8.647450 | 9.552743 | 8.849411 | 8.412751 | 8.099789 | 7.462927 | 6.261123 | 6.005430 | 4.631410 | 5.381667 | 5.262319 | 5.361192 | 5.180934 | 5.813768 | 5.891796 |
| Santa Catarina | 4.142357 | 3.746068 | 3.195435 | 2.687250 | 3.676261 | 3.476774 | 2.838934 | 2.568543 | 3.111619 | 2.826149 | 2.946128 | 2.704941 | 3.970223 | 3.977118 | 4.438998 | 4.251286 | 6.130165 | 6.751974 | 6.397398 | 6.233136 | 7.922351 | 7.540725 | 6.786271 | 6.426735 | 6.561612 | 6.542056 | 6.225881 | 6.346788 | 7.270408 | 6.103167 | 5.787863 | 5.423048 | 5.723819 | 7.212169 | 6.686046 | 5.382586 | 6.352135 | 5.852156 | 5.275229 | 4.314021 | 4.536341 | 3.898636 | 3.757931 | 3.231292 | 3.834735 | 3.499755 | 3.558460 | 3.195803 | 3.828775 | 3.190735 |
Dica 1
Para usar a função pivot_wider(), precisamos indicar os argumentos names_from e values_from.
O argumento names_from é a coluna que queremos usar para nomear as novas colunas. No caso, queremos que cada opção de trimestre seja uma nova coluna.
O argumento values_from é a coluna que queremos usar para preencher os valores das novas colunas. No caso, queremos preencher as novas colunas com a taxa de desocupação.
Sugestões de materiais
Notas de rodapé
É interessante conhecer mais sobre a base de dados que estamos utilizando. O IBGE apresenta alguns conteúdos interessantes, como a página com informações sobre a PNAD Contínua Trimestral, e também a página sobre desemprego que nos ajuda a entender as variáveis presentes.↩︎