library(tidyverse)
data <- read_rds("C:/Users/usuario/Downloads/sidra_4092_arrumado.rds")
dados <- dados |>
filter(ano == max(ano))
dados |>
group_by(uf) |>
mutate(diferenca = perc_desocupacao - last(perc_desocupacao)) |>
ungroup() |>
mutate(uf = fct_reorder(uf, diferenca)) |>
ggplot(aes(x = perc_desocupacao, y = uf)) +
geom_point(aes(color = trimestre_codigo)) +
theme_light()3 Reprodutibilidade e estruturação de projeto
Nesta aula, o objetivo é apresentar o conceito de reprodutibilidade, e apresentar abordagens e ferramentas para estruturar projetos em ciência de dados, buscando garantir a reprodutibilidade dos resultados.
3.1 Introdução à Reprodutibilidade
“Reprodutibilidade é como escovar os dentes. Isso é bom para você, mas leva tempo e esforço. Depois de aprender, torna-se um hábito”. - Irakli Loladze, em pesquisa conduzida por Baker (2016).
A reprodutibilidade é um conceito central na ciência, embora não tenha uma definição única e comum (Gundersen 2021). Ao fazer um levantamento sobre o conceito de reprodutibilidade, Gundersen (2021) elaborou a seguinte definição:
“Reproducibility is the ability of independent investigators to draw the same conclusions from an experiment by following the documentation shared by the original investigators.”
Tradução livre:
“Reprodutibilidade é a capacidade de pesquisadores independentes chegarem às mesmas conclusões de um experimento ao seguir a documentação compartilhada pelos pesquisadores originais.”
A definição prática de reprodutibilidade é frequentemente associada à capacidade de reproduzir os resultados de uma pesquisa a partir dos dados brutos e do código utilizado.
De acordo com Baker (2016), a partir de um questionário realizado pela revista Nature sobre reprodutibilidade com mais de 1500 pesquisadores, vários fatores contribuem para pesquisas não reprodutíveis, como a não disponibilização de códigos, métodos e dados brutos. A figura abaixo apresenta os fatores mais citados pelos respondentes:
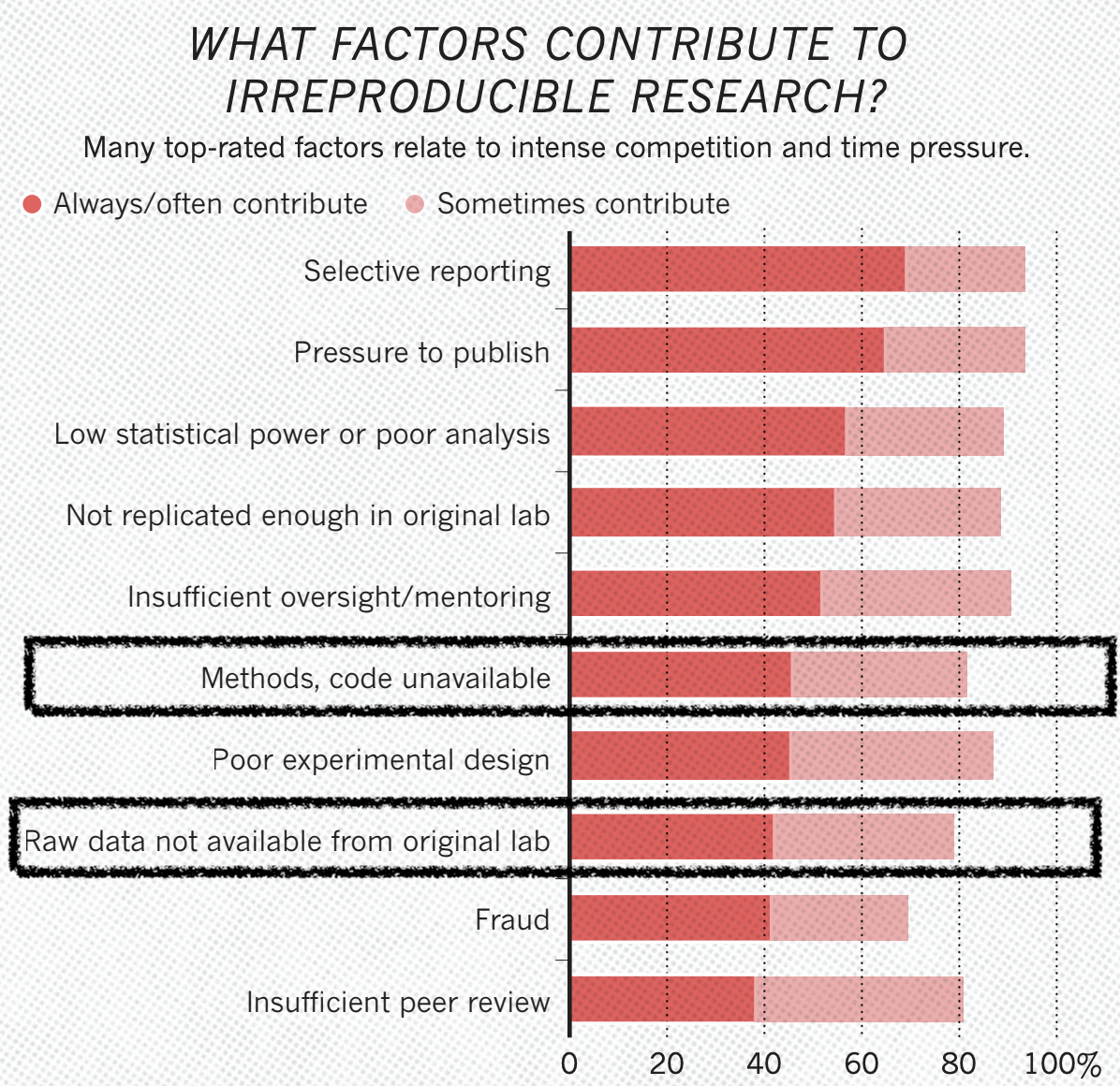
3.1.1 Exercício
- Reflita sobre a seguinte pergunta: Como você acha que a reprodutibilidade está relacionada ao seu trabalho? Se possível, discuta em grupo e posteriormente compartilhe com a turma suas ideias.
3.2 Boas práticas em projetos de análise de dados
Para aumentar a chance de desenvolver um projeto de análise de dados que seja reprodutível, algumas boas práticas podem ser adotadas, como:
não utilizar caminhos absolutos1
evitar o uso de caracteres especiais em caminhos, variáveis e nomes de colunas2. Além disso, utilize nomes descritivos (ex: evite utilizar apenas
xoudf).armazenar os arquivos de maneira consistente
registrar quais são as dependências (versões do R e dos pacotes utilizados)
documentar as análises realizadas
controlar as versões dos arquivos por meio de ferramentas como o Git e GitHub.
compartilhamento de dados brutos, códigos e documentação
Uma prática que pode ajudar a checar a reprodutibilidade de uma análise de dados é solicitar que outra pessoa que trabalha com você tente reproduzir os resultados a partir dos códigos, dados brutos e documentação (Markowetz 2015).
3.2.1 Exercício
Você já teve alguma experiência em que a falta de reprodutibilidade foi um problema? Se sim, o que você aprendeu com essa experiência?
Considerando a seguir e a discussão feita em sala, o que você mudaria no código a seguir?
3.3 Estrutura de projetos
Projetos estruturados são importantes para a reprodutibilidade na ciência de dados. Ferramentas como projetos do RStudio, pacotes em R, controle de versão com Git e GitHub3, relatórios reprodutíveis com Quarto4, {renv} e {targets} ajudam a organizar o trabalho, gerenciar dependências e automatizar processos, aumentando as chances que outras pessoas posam reproduzir os resultados a partir dos códigos e dados brutos. Ao adotar essas práticas, é possível reduzir erros, aumentar a confiabilidade e promover uma ciência mais transparente e colaborativa.
A seguir, vamos apresentar algumas dessas ferramentas e práticas!
3.4 Projetos no RStudio
![]()
Nota
O conteúdo sobre projetos no RStudio foi abordado no curso “Introdução à análise de dados no R”.
O RStudio oferece uma funcionalidade chamada projetos, que facilita a organização e a reprodutibilidade do trabalho em ciência de dados. Ao criar um projeto no RStudio, uma nova pasta é gerada no computador, e o RStudio automaticamente define essa pasta como o diretório de trabalho. Além disso, o RStudio também cria um arquivo com a extensão .Rproj dentro dessa pasta, que contém informações sobre o projeto.
Trabalhar com projetos no RStudio é altamente recomendado, pois ajuda a manter os arquivos organizados e facilita a reprodução do código. Sempre que iniciar uma nova análise de dados, crie um projeto correspondente. Isso garante que todos os arquivos relacionados ao projeto estejam em um único local e evita problemas comuns, como dependência de caminhos absolutos.
É recomendado que sempre trabalhemos em projetos no RStudio, pois isso facilita a organização dos arquivos e a reprodução do código. Portanto, ao começar a trabalhar em uma novo projeto de análise de dados, lembre-se de criar um .Rproj correspondente.
Para manter a organização, salve os arquivos relacionados ao projeto (como scripts, bases de dados e resultados) dentro da pasta principal do projeto. No entanto, é uma boa prática estruturar o projeto em subpastas para separar diferentes tipos de arquivos, como dados, scripts e relatórios.
Um exemplo de estrutura básica de projeto pode incluir as seguintes subpastas:
dados/: Para armazenar bases de dados.scripts/: Para salvar scripts R utilizados na análise.relatorios/: Para guardar relatórios gerados.
3.4.1 Exercício: preparando o projeto do curso
No RStudio, crie um novo projeto para ser utilizado ao longo do curso. Lembre-se de criar o projeto em uma pasta que você possa acessar facilmente.
Dentro do projeto, crie as seguintes pastas para organizar os arquivos:
dados/dados_output/scripts/relatorios/
Você pode criar as pastas manualmente ou utilizar a função dir.create() para criar as pastas:
dir.create("dados")
dir.create("dados_output")
dir.create("scripts")
dir.create("relatorios")- Vamos também fazer download do arquivo
sidrar_4092_bruto_2.csv, para usar em exemplos de aulas posteriores:
# Arquivo .csv (texto separado por ponto e vírgula)
download.file(
url = "https://github.com/ipeadata-lab/curso_r_intro_202409/raw/refs/heads/main/dados/sidrar_4092_bruto_2.csv",
destfile = "dados/sidrar_4092_bruto_2.csv",
mode = "wb")3.5 {renv}: gerenciando dependências
![]()
O R e seus pacotes estão em constante evolução, com novas versões sendo lançadas regularmente para corrigir erros, adicionar funcionalidades e melhorar a eficiência. No entanto, essas atualizações podem introduzir mudanças que “quebram” análises anteriores, especialmente se as versões dos pacotes usados em um projeto não forem registradas. Para evitar esses problemas e garantir que as análises sejam reprodutíveis ao longo do tempo, podemos utilizar ferramentas que ajudem a gerenciar as dependências do projeto.
O pacote {renv} é uma ferramenta que permite gerenciar as dependências de pacotes em projetos R. Ele registra quais foram os pacotes utilizados, quais é a versão de cada um deles, e a fonte de instalação (se foram instalados do CRAN, GitHub, R Universe, Bioconductor, etc). Isso possibilita que o ambiente seja reproduzido em qualquer máquina ou momento, mesmo se o R ou os pacotes forem atualizados.
O {renv} é especialmente útil em projetos colaborativos, em que diferentes pessoas podem estar trabalhando no mesmo projeto, ou em projetos que serão retomados após um longo período de tempo.
Um conceito importante do {renv} é o isolamento de ambiente. Isso significa que o {renv} possibilita armazenar as bibliotecas de pacotes do projeto em uma pasta específica, separada das bibliotecas globais do R. Isso evita conflitos entre versões de pacotes e garante que o ambiente de pacotes do projeto seja consistente e reprodutível.
Apesar de poderoso, o {renv} pode não ser necessário para projetos muito simples ou temporários.
3.5.1 Arquivo renv.lock
O {renv} registra as dependências do projeto no arquivo renv.lock, que é um arquivo que contém informações sobre as versões dos pacotes instalados. Com esse arquivo, é possível recriar o ambiente de pacotes exatamente como ele estava quando o arquivo foi gerado. Isso é útil para garantir a reprodutibilidade do projeto e evitar problemas com pacotes desatualizados.
Atenção: o arquivo renv.lock não deve ser alterado manualmente.
NotaExpanda para ver um exemplo de conteúdo do
renv.lock
No exemplo abaixo, temos um exemplo do conteúdo do renv.lock. Observe que está registrado que estamos usando o R versão 4.4.1 e o pacote readr (deixamos apenas um pacote para servir de exemplo, mas o arquivo contém informações sobre todos os pacotes utilizados no projeto):
{
"R": {
"Version": "4.4.1",
"Repositories": [
{
"Name": "CRAN",
"URL": "https://cloud.r-project.org"
}
]
},
"Packages": {
"readr": {
"Package": "readr",
"Version": "2.1.5",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"R6",
"cli",
"clipr",
"cpp11",
"crayon",
"hms",
"lifecycle",
"methods",
"rlang",
"tibble",
"tzdb",
"utils",
"vroom"
],
"Hash": "9de96463d2117f6ac49980577939dfb3"
}
}
}- 1
- Versão do R utilizada, e de qual repositório ele foi instalado.
- 2
- Lista de pacotes utilizados (essa lista foi cortada para aparecer apenas um pacote, como exemplo).
- 3
- Informações sobre o pacote instalado: nome, versão, repositório de origem, dependências e hash.
- 4
-
Dependências do pacote instalado: quais pacotes são necessários para que o pacote
readrfuncione corretamente?
3.5.2 Principais funções do {renv}
Para começar a utilizar o {renv} em um projeto, podemos utilizar a função renv::init(). Isso criará uma pasta renv/ e um arquivo renv.lock, que registrará as dependências do projeto. Além disso, o {renv} armazenará as bibliotecas de pacotes do projeto na pasta renv/library (chamamos isso de isolamento).
renv::init()Para verificar o status do ambiente e quais pacotes estão instalados, podemos usar a função renv::status():
renv::status()A função renv::snapshot() é utilizada para registrar/atualizar as dependências do projeto no arquivo renv.lock. Isso é útil quando novos pacotes são instalados ou atualizados, e queremos registrar essas mudanças.
renv::snapshot()Para restaurar o ambiente de pacotes de um projeto a partir do arquivo renv.lock, podemos utilizar a função renv::restore():
renv::restore()
Nota
Também é possível utilizar a função renv::snapshot() com um projeto que não foi iniciado com {renv} (iniciado com o renv::init()).
Neste caso, ele registrará o estado atual das dependências nos caminhos das bibliotecas atuais. Isso torna possível restaurar os pacotes atuais, fornecendo portabilidade e reprodutibilidade leves sem o isolamento de ambiente.
3.5.3 Exercício 1
Neste exercício, vamos praticar a utilização do {renv} em um projeto, utilizando o isolamento de ambiente.
Abra o projeto criado no exercício anterior (ou crie um novo projeto, se preferir).
Inicie o
{renv}no projeto utilizando a funçãorenv::init().
NotaExemplo de output da função
renv::init()
renv::init()renv: Project Environments for R
Welcome to renv! It looks like this is your first time using renv.
This is a one-time message, briefly describing some of renv's functionality.
renv will write to files within the active project folder, including:
- A folder 'renv' in the project directory, and
- A lockfile called 'renv.lock' in the project directory.
In particular, projects using renv will normally use a private, per-project
R library, in which new packages will be installed. This project library is
isolated from other R libraries on your system.
In addition, renv will update files within your project directory, including:
- .gitignore
- .Rbuildignore
- .Rprofile
Finally, renv maintains a local cache of data on the filesystem, located at:
- "/cloud/home/r217847/.cache/R/renv"
This path can be customized: please see the documentation in `?renv::paths`.
Please read the introduction vignette with `vignette("renv")` for more information.
You can browse the package documentation online at https://rstudio.github.io/renv/.
Do you want to proceed? [y/N]: y- "/cloud/home/r217847/.cache/R/renv" has been created.
The following package(s) will be updated in the lockfile:
# RSPM -----------------------------------------------------------------------
- renv [* -> 1.0.11]
The version of R recorded in the lockfile will be updated:
- R [* -> 4.4.2]
- Lockfile written to "/cloud/project/renv.lock".
Restarting R session...
- Project '/cloud/project' loaded. [renv 1.0.11]Observe no seu projeto se o arquivo
renv.lockfoi criado e a pastarenv/foi gerada. Abra o arquivorenv.lockpara verificar as informações registradas.Utilize a função
renv::status()para verificar o status do ambiente e quais pacotes estão instalados.
NotaExemplo de output da função
renv::status()
renv::status()
#> No issues found -- the project is in a consistent state.Instale o pacote
palmerpenguinsutilizando a funçãoinstall.packages("palmerpenguins")no console.Crie um RScript, escreva
library(palmerpenguins)e salve-o (dentro do projeto).Utilize novamente a função
renv::status()para verificar o status do ambiente e quais pacotes estão instalados.
NotaExemplo de output da função
renv::status()
renv::status()The following package(s) are in an inconsistent state:
package installed recorded used
palmerpenguins y n y
See `?renv::status` for advice on resolving these issues.- Utilize a função
renv::snapshot()para registrar as dependências do projeto no arquivorenv.lock.
NotaExemplo de output da função
renv::snapshot()
renv::snapshot()The following package(s) will be updated in the lockfile:
# CRAN -----------------------------------------------------------------------
- palmerpenguins [* -> 0.1.1]
Do you want to proceed? [Y/n]:y- Lockfile written to "/cloud/project/renv.lock".- Observe no arquivo
renv.lockse as informações sobre o pacotepalmerpenguinsforam registradas.
3.5.4 Exercício 2
Neste exercício, o objetivo é praticar a restauração do ambiente de pacotes de um projeto a partir do arquivo renv.lock.
Crie um novo projeto no RStudio, para que possamos trabalhar neste exercício com o
{renv}(não utilize o mesmo do exercício 1).Faça o download deste arquivo
renv.lockque utilizaremos de exemplo, e salve na pasta do projeto. Você pode fazer o download manualmente, ou utilizar o código abaixo para baixar o arquivo diretamente no R:
download.file(
url = "https://raw.githubusercontent.com/ipeadata-lab/curso_r_intermediario_202501/refs/heads/main/exercicios/renv-2/renv.lock",
destfile = "renv.lock",
mode = "wb")Abra o arquivo
renv.lockpara verificar as informações registradas.Utilize a função
renv::restore()para restaurar o ambiente de pacotes do projeto a partir do arquivorenv.lock. Quando solicitado, escolha a opção para não isolar o ambiente de pacotes (2: Do not activate the project and use the current library paths.).
NotaExemplo de output da função
renv::restore()
renv::restore()
renv: Project Environments for R
Welcome to renv! It looks like this is your first time using renv.
This is a one-time message, briefly describing some of renv's functionality.
renv will write to files within the active project folder, including:
- A folder 'renv' in the project directory, and
- A lockfile called 'renv.lock' in the project directory.
In particular, projects using renv will normally use a private, per-project
R library, in which new packages will be installed. This project library is
isolated from other R libraries on your system.
In addition, renv will update files within your project directory, including:
- .gitignore
- .Rbuildignore
- .Rprofile
Finally, renv maintains a local cache of data on the filesystem, located at:
- "/cloud/home/r217847/.cache/R/renv"
This path can be customized: please see the documentation in `?renv::paths`.
Please read the introduction vignette with `vignette("renv")` for more information.
You can browse the package documentation online at https://rstudio.github.io/renv/.
Do you want to proceed? [y/N]: y- "/cloud/home/r217847/.cache/R/renv" has been created.
It looks like you've called renv::restore() in a project that hasn't been activated yet.
How would you like to proceed?
1: Activate the project and use the project library.
2: Do not activate the project and use the current library paths.
3: Cancel and resolve the situation another way.
Atenção neste ponto!
A opção 1 (
Activate the project and use the project library) é a opção que irá ativar o ambiente de pacotes do projeto, isolando as bibliotecas de pacotes do projeto das bibliotecas globais do R.A opção 2 (
Do not activate the project and use the current library paths) é a opção que não irá ativar o ambiente de pacotes do projeto, e os pacotes serão instalados nas bibliotecas globais do R.
2Selection: 2
The following package(s) will be updated:
# CRAN -----------------------------------------------------------------------
- parzer [* -> 0.4.1]
- Rcpp [* -> 1.0.13-1]
- withr [* -> 3.0.2]
Do you want to proceed? [Y/n]: yy# Downloading packages -------------------------------------------------------
- Querying repositories for available source packages ... Done!
- Downloading Rcpp from CRAN ... OK [3.3 Mb]
- Downloading parzer from CRAN ... OK [433.6 Kb]
- Downloading withr from CRAN ... OK [100.8 Kb]
Successfully downloaded 3 packages in 2.1 seconds.
# Installing packages --------------------------------------------------------
- Installing Rcpp ... OK [built from source and cached in 26s]
- Installing withr ... OK [built from source and cached in 3.3s]
- Installing parzer ... OK [built from source and cached in 26s]
Session restored from your saved work on 2025-Jan-20 10:58:30 UTC (18 minutes ago)- Verifique no seu projeto se o pacote
parzerestá disponível para uso.
library(parzer)3.6 Introdução ao {targets}
![]()
O pacote {targets} é uma ferramenta para gerenciamento de pipelines reprodutíveis e escaláveis em R. Ele foi projetado para ajudar a organizar e automatizar análises de dados complexas, garantindo que todos os passos da análise sejam executados na ordem correta e de forma eficiente.
O {targets} utiliza o conceito de pipelines: cada etapa da análise é definida como um “alvo” (ou target), e as dependências entre essas etapas são gerenciadas automaticamente. Isso significa que, quando algo é alterado em uma etapa inicial, o {targets} identifica quais etapas subsequentes precisam ser reexecutadas e atualiza apenas essas partes, economizando tempo e esforço.
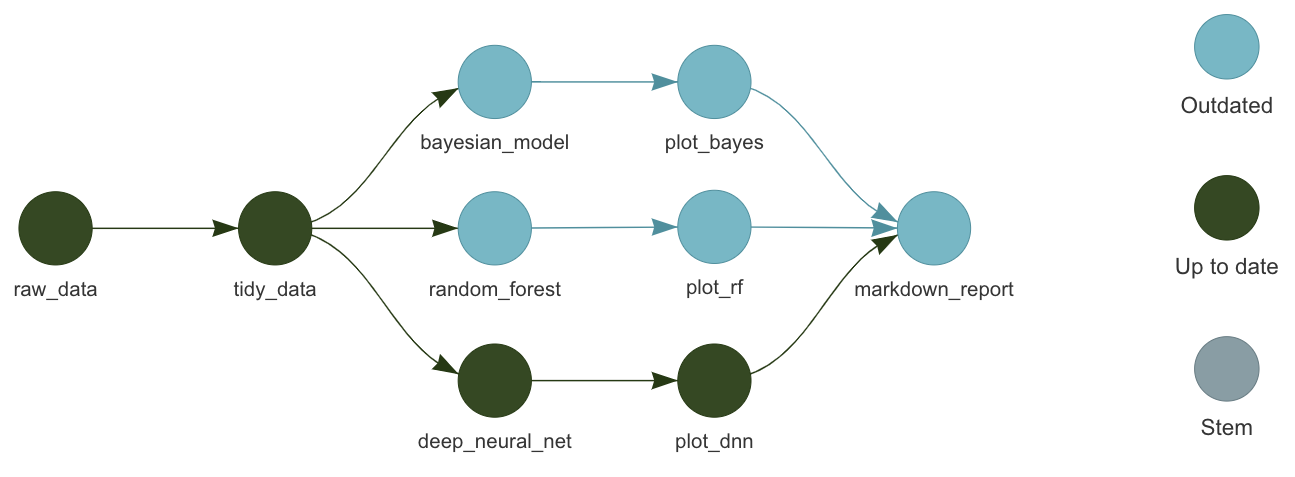
O {targets} é especialmente útil em análises que incluem múltiplas etapas interdependentes, como pré-processamento, modelagem e visualização. Ele também é indicado para situações em que se trabalha com grandes volumes de dados ou análises que demandam muito tempo de execução.
Embora seja uma ferramenta poderosa, o {targets} pode ser excessivo para análises simples que consistem em poucas etapas. Ele é mais indicado para fluxos de trabalho complexos.
3.6.1 Materiais de referência sobre targets
Apresentação “Reproducible computation at scale in R” por Will Landau.
3.7 Outros pacotes citados em aula
{reprex}- este pacote nos auxilia a criar exemplos reprodutíveis. Ele é útil para compartilhar dúvidas em fóruns, reportar bugs e criar tutoriais.{conflicted}- este pacote nos ajuda a gerenciar conflitos de funções. Ele é útil quando dois pacotes possuem funções com o mesmo nome, e precisamos escolher qual função utilizar.{groundhog}- este pacote nos ajuda a utilizar versões específicas de pacotes.
3.8 Materiais
O material do curso “Relatórios reprodutíveis com R”, ministrado por Beatriz Milz no programa de Verão do IME-USP, foi utilizado como base para a elaboração de parte do material desta aula.
3.9 Material complementar
- Capítulos do livro “R para Ciência de Dados” (2 ed) por Hadley Wickham, Mine Çetinkaya-Rundel, e Garrett Grolemund:
3.10 Referências citadas
Baker, Monya. 2016. «1, 500 scientists lift the lid on reproducibility». Nature 533 (7604): 452–54. https://doi.org/10.1038/533452a.
Gundersen, Odd Erik. 2021. «The fundamental principles of reproducibility». Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 379 (2197): 20200210. https://doi.org/10.1098/rsta.2020.0210.
Markowetz, Florian. 2015. «Five selfish reasons to work reproducibly». Genome Biology 16 (1). https://doi.org/10.1186/s13059-015-0850-7.
Os conceitos diretório de trabalho, caminhos absolutos e caminhos relativos foram abordados na aula sobre diretórios de trabalho e projetos do curso “Introdução à análise de dados no R”.↩︎
Caso queira revisar este tópico, recomendamos a leitura da seção sobre boas práticas para nomear objetos no R do curso “Introdução à análise de dados no R”.↩︎
Será abordado na aula sobre introdução ao controle de versão com Git e GitHub.↩︎
Será abordado na aula sobre produção de relatórios com Quarto.↩︎