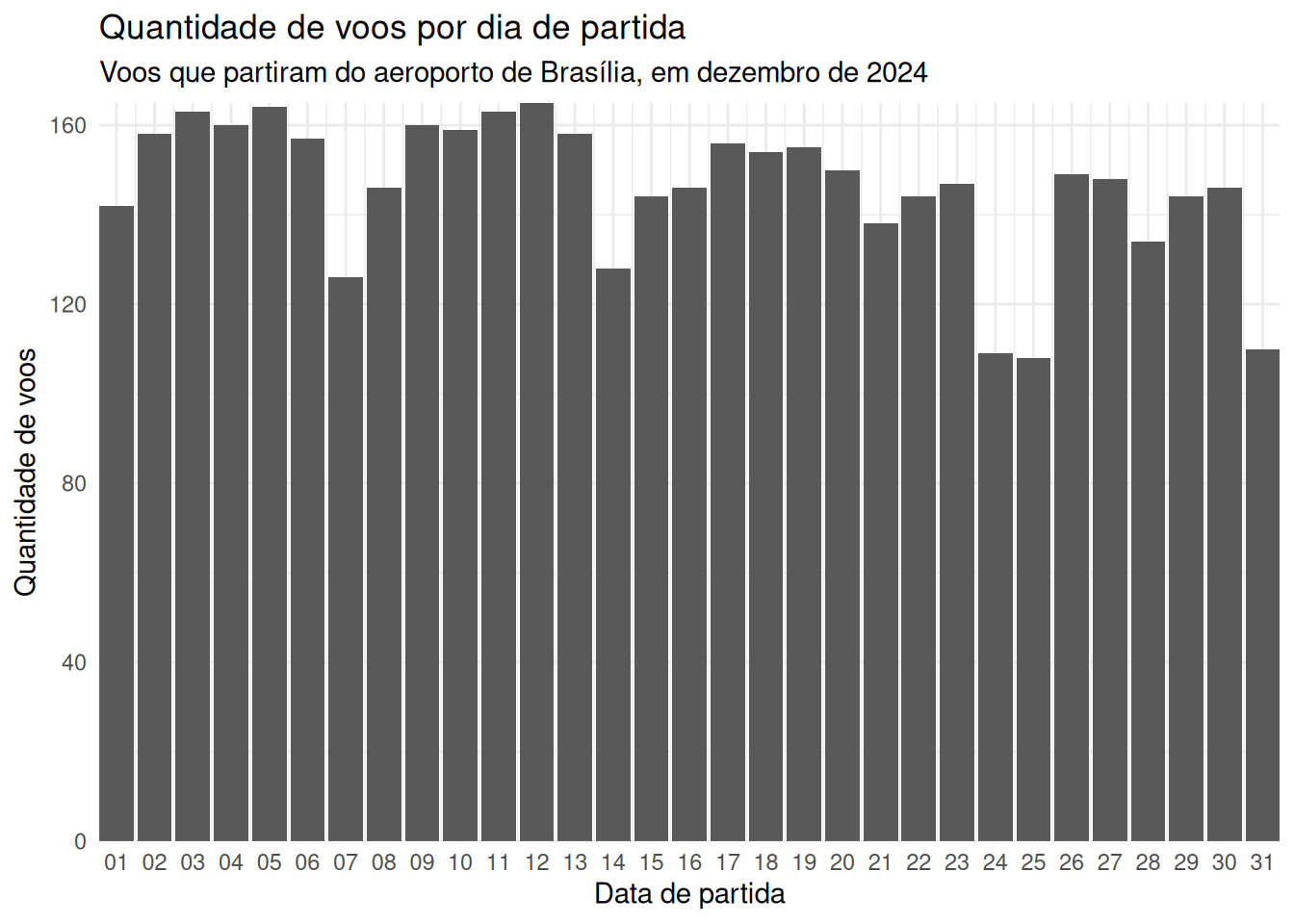
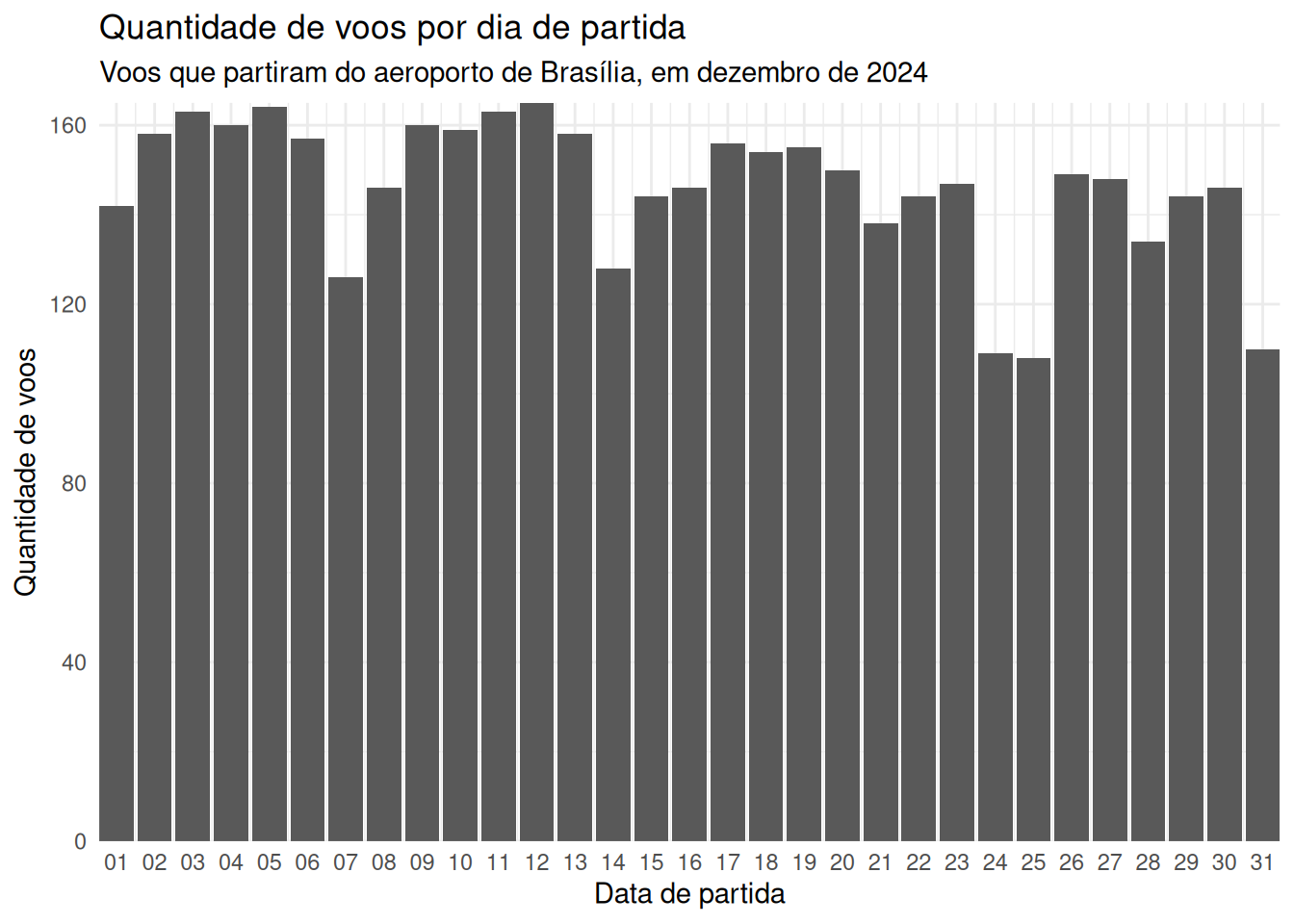
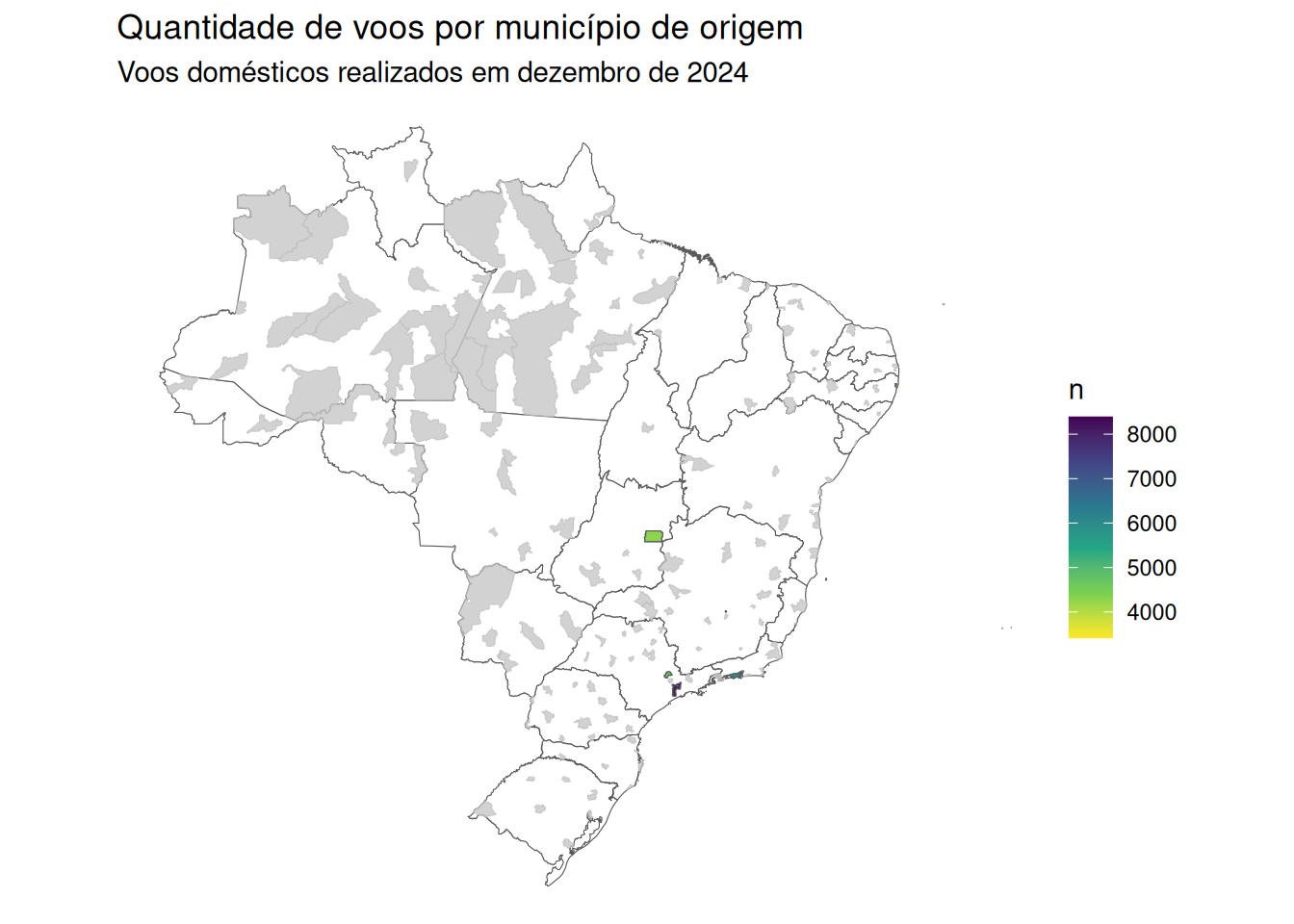
Rows: 82,003
Columns: 26
$ id_basica <dbl> 33821878, 33972533, 33819746, 33819747, 33914237…
$ id_empresa <dbl> 1002650, 1001070, 1007570, 1007570, 1000896, 100…
$ nm_empresa <chr> "DHL AERO EXPRESO", "AEROVÍAS DE MÉXICO S.A DE C…
$ dt_referencia <date> 2024-12-01, 2024-12-01, 2024-12-01, 2024-12-01,…
$ ds_di <chr> "INCLUSÃO DE ETAPA EM UM VOO PREVISTO EM HOTRAN"…
$ ds_grupo_di <chr> "REGULAR", "REGULAR", "REGULAR", "REGULAR", "REG…
$ ds_natureza_etapa <chr> "INTERNACIONAL", "INTERNACIONAL", "INTERNACIONAL…
$ hr_partida_real <time> 13:35:00, 10:15:00, 05:34:00, 19:45:00, 20:24:0…
$ dt_partida_real <chr> "01/12/2024", "01/12/2024", "01/12/2024", "30/11…
$ id_aerodromo_origem <dbl> 467, 301, 301, 609, 66, 66, 301, 500, 301, 301, …
$ nm_aerodromo_origem <chr> "MIAMI INTERNATIONAL AIRPORT", "GUARULHOS - GOVE…
$ nm_municipio_origem <chr> "MIAMI, FLORIDA", "GUARULHOS", "GUARULHOS", "PUN…
$ sg_uf_origem <chr> NA, "SP", "SP", NA, NA, NA, "SP", NA, "SP", "SP"…
$ nm_regiao_origem <chr> NA, "SUDESTE", "SUDESTE", NA, NA, NA, "SUDESTE",…
$ nm_pais_origem <chr> "ESTADOS UNIDOS DA AMÉRICA", "BRASIL", "BRASIL",…
$ nm_continente_origem <chr> "AMÉRICA DO NORTE", "AMÉRICA DO SUL", "AMÉRICA D…
$ hr_chegada_real <time> 22:46:00, 19:01:00, 11:42:00, 03:28:00, 05:42:0…
$ dt_chegada_real <dbl> 45627, 45627, 45627, 45627, 45628, 45627, 45628,…
$ id_aerodromo_destino <dbl> 162, 466, 609, 301, 301, 301, 500, 301, 66, 66, …
$ nm_aerodromo_destino <chr> "VIRACOPOS", "BENITO JUAREZ INTL", "PUNTA CANA",…
$ nm_municipio_destino <chr> "CAMPINAS", "MEXICO", "PUNTA CANA", "GUARULHOS",…
$ sg_uf_destino <chr> "SP", NA, NA, "SP", "SP", "SP", NA, "SP", NA, NA…
$ nm_regiao_destino <chr> "SUDESTE", NA, NA, "SUDESTE", "SUDESTE", "SUDEST…
$ nm_pais_destino <chr> "BRASIL", "MÉXICO", "REPÚBLICA DOMINICANA", "BRA…
$ nm_continente_destino <chr> "AMÉRICA DO SUL", "AMÉRICA DO NORTE", "AMÉRICA C…
$ dt_sistema <dttm> 2025-01-04 01:00:02, 2025-01-10 01:00:09, 2025-…